When uploading a >5Mb file to an AWS S3 bucket, the AWS SDK/CLI automatically splits the upload to multiple HTTP PUT requests. It’s more efficient, allows for resumable uploads, and — if one of the parts fails to upload — the part is re-uploaded without stopping upload progress.
However, there lies a potential pitfall with multipart uploads:
If your upload was interrupted before the object was fully uploaded, you’re charged for the uploaded object parts until you delete them.
As a result, you may experience a hidden increase in storage costs which isn’t apparent right away.
Read on to see how to identify uploaded object parts, and how to reduce costs in the event that there are unfinished multipart uploads.

How can I find uploaded object parts in AWS S3 Console?
This is the interesting part, you can not see these objects in AWS S3 Console.
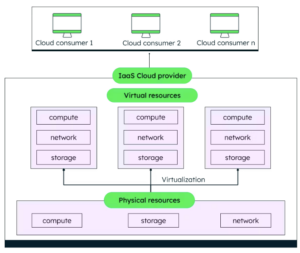
For the purpose of this article, I created an S3 bucket and uploaded a 100Gb file. I stopped the upload process after 40Gb were uploaded.
When I accessed the S3 Console, I could see that there are 0 objects in the bucket and that the S3 console is not displaying the 40Gb that were uploaded (multipart)
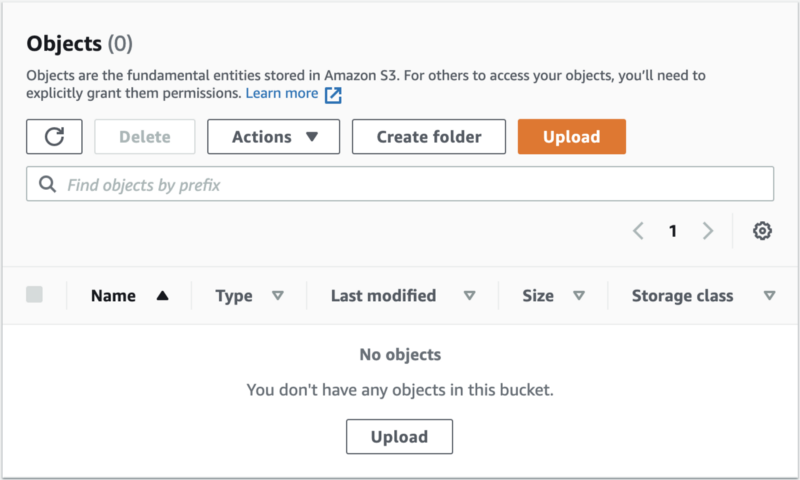
Then I clicked on the Metrics tab, and I saw that the bucket size is 40Gb
It may take several hours for updated metrics to appear.
This means that even though you can’t see the object in the console because the upload didn’t finish, you are still being charged for the parts that were already uploaded.
How is this addressed in the real world?
I’ve approached several colleagues at various companies that run AWS account with a substantial AWS S3 monthly usage.
The majority of these colleagues all had between +100Mb up to +10Tb of unfinished multipart uploads. The general consensus was that the larger the S3 usage and the older the account, the more incomplete objects existed.
Calculating the multipart part-size of a single object
First, within the AWS CLI, list the current multipart objects with the following command:
aws s3api list-multipart-uploads --bucket <bucket-name>
This outputs a list of all the objects that are incomplete and have multiple parts:
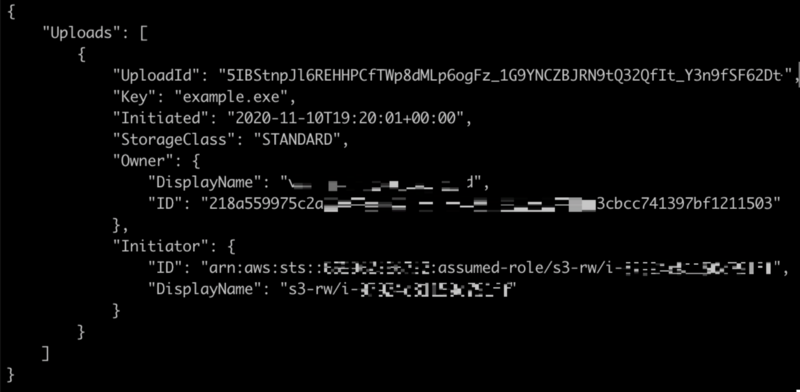
Then, list all the objects in the multipart upload by using the list-parts command with the “UploadId” value:
aws s3api list-parts --upload-id 5IBStnpJl6REH... --bucket <bucket-name> --key example.exe
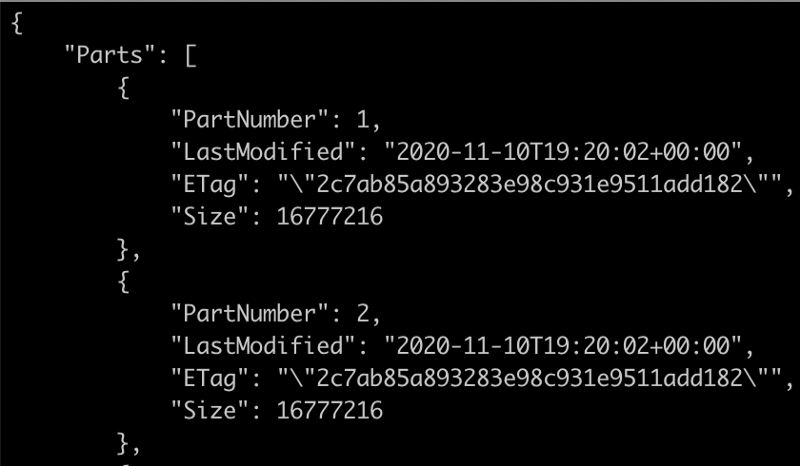
Next, sum the size (in bytes) of all the uploaded parts and convert the output to Gb by using a JQ (command-line JSON processor):
jq '.Parts | map(.Size/1024/1024/1024) | add'
If you want to delete a multipart upload object manually, you can run:
aws s3api abort-multipart-upload --bucket <bucket-name> --key example.exe --upload-id 5IBStnpJl6REH...
How to stop being charged for unfinished multipart uploads?
By setting at the bucket level, you can create a lifecycle rule that will automatically delete incomplete multipart objects after a couple of days.
“An S3 Lifecycle configuration is a set of rules that define actions that Amazon S3 applies to a group of objects.” (AWS documentation).
Below are two solutions:
- A manual solution for existing buckets, and
- An automatic solution for creating a new bucket.
Deleting multipart uploads in existing buckets
In this solution, you’ll create an object lifecycle rule to remove old multipart objects in an existing bucket.
Caution: Be careful when defining a Lifecycle rule. A definition error may delete existing objects in your bucket.
First, open the AWS S3 console, select the desired bucket, and navigate to the Management tab.
Under Lifecycle rules, click on Create lifecycle rule.
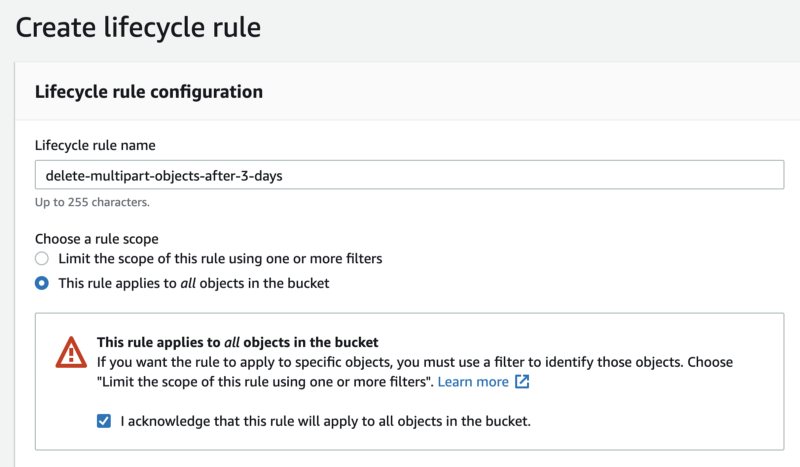
Then name the lifecycle rule and select the rule’s scope for all objects in the bucket.
Check the box for “I acknowledge that this rule will apply to all objects in the bucket”.
Next, navigate to Lifecycle rule actions and check the box for “Delete expired delete markers or incomplete multipart upload”.
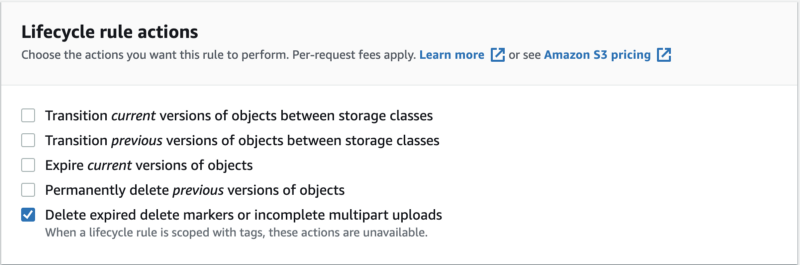
Check the box for “Delete incomplete multipart uploads”, and set the Number of days according to your needs (I believe that three days is enough time to finish uncompleted uploads).
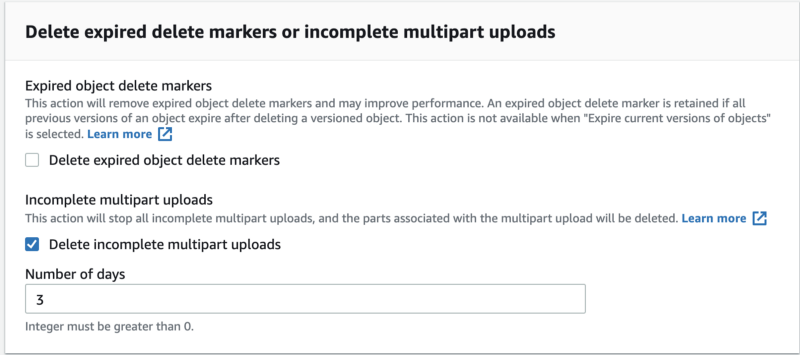
Post successful completion of the steps above, the multipart files that were uploaded will be deleted, but not immediately (it’ll take a little while).
Two things to note:
- Delete operations are free of charge.
- Once you have defined the lifecycle rule, you are not charged for the data that will be deleted.
Creating a lifecycle rule for new buckets
In this solution, you’ll create a lifecycle rule that applies automatically every time a new bucket is created.

This uses a straightforward lambda automation script, which is triggered every time a new bucket is created. This lambda function implements a lifecycle rule for deleting all the multipart objects which are 3 days old.
Note: Since EventBridge runs only in the region in which it is created, you must deploy the lambda function in each region you operate.
S3 Management Console — Watch Video
How to implement this automation?
- Enable AWS CloudTrail trail. Once you configure the trail, you can use AWS EventBridge to trigger a Lambda function.
- Create a new lambda function, with Python 3.8 as the function Runtime.
- Paste the code below (Github gist):
4. Select create function.
5. Scroll to the top of the page, under Trigger select ‘Add trigger’ and for the Trigger configuration, choose EventBridge.
Then create a new rule and give the rule a name and description.
6. Choose Event pattern in rule type, choose Simple Storage Services (S3) and AWS API call via CloudTrail in the two boxes below
Under the Detail box, choose CreateBucket in Operation
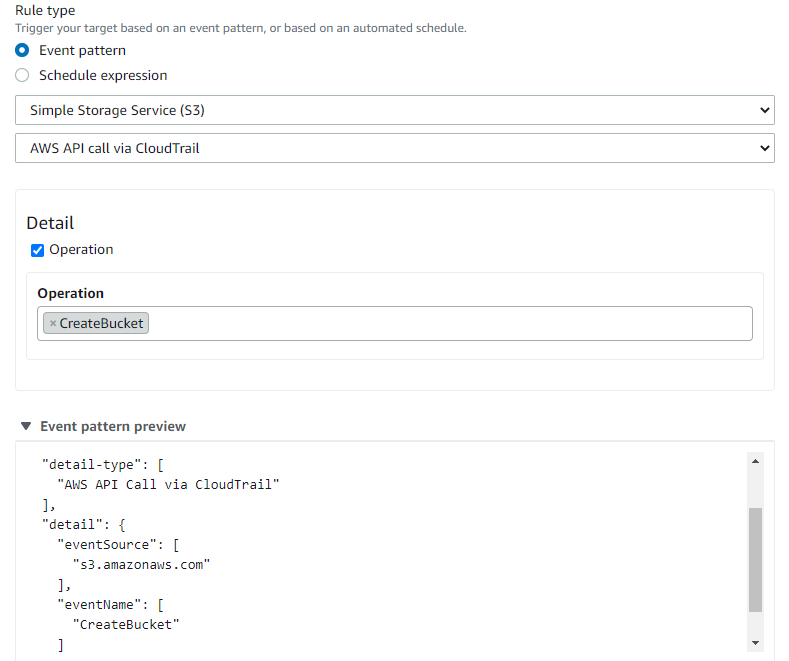
Scroll down and click the Add button.
7. Scroll down to the Basic settings tab, and select Edit → IAM role and attach the policy as given below.
This policy will allow the lambda function to create a lifecycle configuration to all the buckets in the AWS account.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:PutLifecycleConfiguration",
"Resource": "*"
}
]
}
8. Create a bucket to check that the lambda function is functioning correctly.
9. That’s it! Now every time you create a new bucket (in the region you configured), the lambda function will automatically create a lifecycle for that bucket.
Thanks for reading! To stay connected, follow us on the DoiT Engineering Blog, DoiT Linkedin Channel, and DoiT Twitter Channel. To explore career opportunities, visit https://careers.doit.com.