When cloud cost optimization strategies are more trouble than they’re worth, take the effortless route to cloud savings
For all of the scalability, reliability and flexibility the public cloud offers, there is still no such thing as a free lunch. Cloud providers like Amazon Web Services and Google Cloud allow you to use and pay for compute power and services as you need them, but doing so on a purely on-demand basis incurs high costs. At some point, on-demand public cloud usage becomes cost-prohibitive.
You can deploy various methods to better manage your cloud spend, such as committing to usage or spend amounts well in advance, or using spot instances at heavily discounted rates. However, both of these cost optimization strategies require time and resources to execute them properly. The question then becomes not “how much money can you save?” but rather “is the output worth its effort?”
Let’s look at both of these strategies to get a better understanding of what each entails and how they might be optimized to make the effort worthwhile for your organization.
Compute Commitments / Reservations
With compute typically representing more than half of your total cloud bill, optimizing this cost will likely impact your overall spend most. This is why public cloud providers like AWS offer significant discounts in exchange for reserving or committing your usage in advance. These commitment programs, known as Reserved Instances or Savings Plans on AWS, come in one- or three-year terms, with three-year commitments naturally offering the largest discounts.
However, leveraging these savings opportunities requires highly accurate forecasts of your usage over the term of the commitment. If you overprovision and reserve more compute usage than you need, you’ll end up wasting money on unused workloads (which recalls the old days of data center usage and CapEx spending models). On the other hand, if you underprovision and then need more instances down the line, you’ll either have to start again with forecasting and provisioning for a new commitment, or spend significantly higher rates for on-demand instances.
Making matters more complicated are all of the different variables that are difficult to factor into the terms of a commitment, such as:
- code changes that increase or decrease the compute requirements of an app
- success/virality potential of new products and services
- macroeconomic influences such as inflation and supply chain mechanics that cannot be controlled yet can still affect your cloud usage
Usually, companies end up reserving as much as possible in three-year commitments to establish a minimum baseline and then pile on top one-year reservations based on the specific VM types, sizes and regions that are required for their applications.
This generally leads to the creation of a constantly changing calendar of discounts whose workload targets, specifications and expiration dates must be tracked and managed throughout the year by at least one dedicated person – if not a whole team. These individuals must have cloud expertise and be able to relate usage to overall business objectives. And naturally, the cost of recruiting, training and retaining such a specialized team will likely erode any savings.
Not surprisingly, this is a significant hurdle for many organizations to overcome, particularly for younger companies with limited resources and growth-focused mindsets. Most startups can’t afford to divert their limited DevOps resources’ time and attention to managing commitments, and choose to focus on development and growth instead of cost and usage management.
Even larger, better resourced and more digitally mature enterprises can struggle to keep up with their commitment portfolio. The more complex the cloud environment, the more challenging the management logistics become as compute needs and consumption rates can vary between individual teams within the organization, ownership over provisioning and tracking of cloud usage can change, and environments between teams become more differentiated.
Spot Instances
One of the most effective ways to reduce your cloud spend on AWS is by deploying Spot Instances wherever possible. With savings of up to 90% from on-demand pricing, this method offers even bigger discounts than three-year commitments, but with a pretty significant catch: Spot Instances are sold as last-minute deals on unused on-demand instances (think a bakery selling off its inventory at the end of the day), but they can also be reclaimed by the cloud provider with just two minutes’ notice. This caveat makes many think twice about adopting Spot instances, as you’re likely to choose uptime in a tradeoff between the uptime of your applications and savings.
Spot Instances can be managed on AWS with Auto Scaling Groups (ASGs), but deploying them naturally requires a certain degree of flexibility with regard to the instance types and Availability Zones that you request, as it’s always possible none will be available to you at your target specifications. ASGs must also be manually configured and regularly tuned to ensure that your compute needs are still being met without any meaningful interruptions. This is another manual and tedious process, and if there’s an incorrect configuration, it might not even work.
Despite Spot Instances’ clear limitations, you can deploy strategies to optimize their use. One such strategy is capacity rebalancing, which helps maintain availability (based on AWS’s Instance Rebalance Recommendations). This sends a preemptive signal when a Spot Instance is likely to be turned off, which can be a big help compared to AWS’s standard two-minute warning – provided that you have someone available to manage the change.
Is the juice worth the squeeze?
The unfortunate truth is that there’s no magic formula for determining how much the management of all these cost optimization strategies will cost you. It depends heavily on both the size and complexity of your cloud environment, your current and future business objectives, and the amount of expertise at your disposal within your organization. For example, is it cheaper to overcommit to a certain extent at a lower price than it is to undercommit and use on-demand pricing for the rest? And if you choose the latter option, how valuable is the flexibility that it offers compared to the extra money that a larger commitment would save?
Going a bit deeper, is your team able to plan and manage these programs, or will you have to hire new personnel with the requisite skills and expertise? And if so, is that the best use of your operating budget, or would that money be better spent on product development or go-to-market strategies?
Many companies decide that all these questions and the time spent answering them is more trouble than it’s worth. It’s hard to argue with them on that, especially considering that longer-term commitments often come at the expense of engineering flexibility, as new projects or features not factored into the original forecast might have to be put on hold until new resources can be provisioned. Are you okay with your product roadmap being constrained by operating budget decisions that were made over a year ago?
However, alternative solutions to these problems provide much-needed cost savings without soaking up so much of your infrastructure team’s time and energy.
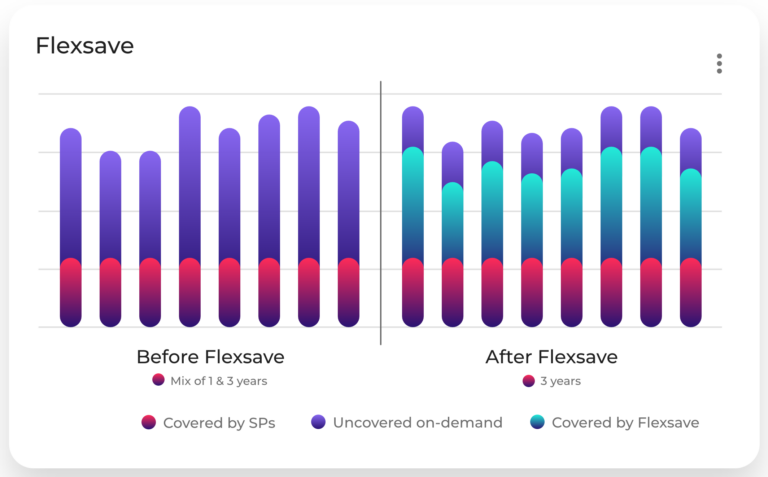
DoiT Flexsave helps solve the challenge of commitment management by enabling automated management of compute discounts. It uses machine learning to continuously monitor your cloud usage and identify compute instances that are not covered by existing commitments. It then applies one-year discount rates on applicable workloads to address that coverage gap. This enables the flexibility of on-demand usage without the worry of soaring infrastructure costs. You can even purchase as many three-year commitments as you want to maximize your savings, and then let Flexsave cover the rest.
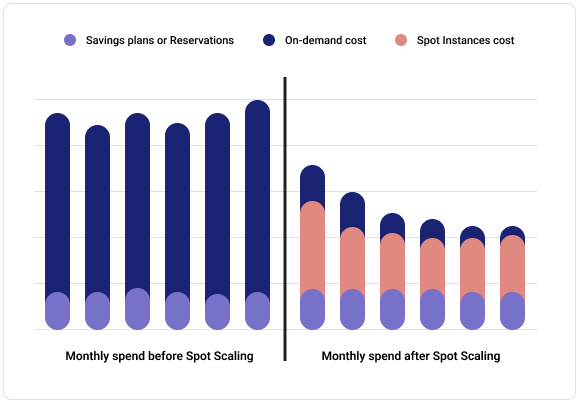
Meanwhile, DoiT Spot Scaling helps you run your workloads reliably on AWS Spot Instances without having to worry about interruptions. Autonomously monitoring your ASGs, Spot Scaling recommends best practice configurations and replaces on-demand instances with the heavily discounted Spot Instances when applicable, with fallback to on-demand for situations where there is zero spot capacity in the market. Moreover, Spot Scaling is the only solution in the market that lets you keep all of your savings, taking nothing as a commission.
To learn more about DoiT-recommended cost optimization strategies, get in touch with an expert today, or check out our recent ebook, The Cost Conscious Cloud.