Most data professionals dabble in data transformation, but which product is right for you?
Some of the most significant issues faced by DoiT customers are related to the transformation and processing of data from various sources to numerous targets.
Many of our customers utilize Data Warehousing services such as Snowflake or Google BigQuery to store and manage their data. They want to learn how that data can be managed effectively without manually running & maintaining data pipeline codes themselves.
In the past, with relational databases and old-fashioned data warehouse infrastructures, this was the realm of the ETL tool—whereby tools such as SSIS, Informatica, or SAS Data Integration Studio were used to manage source-to-target extraction, transformation, and loading this managed data into a data warehouse of choice.
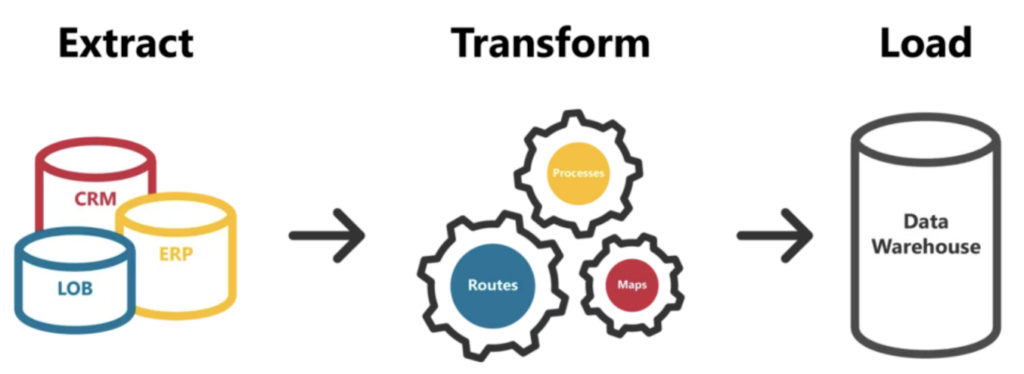
But the industry has evolved with the emergence of Cloud Data Warehouses such as Snowflake, BigQuery, Redshift, etc. These next-generation platforms, given their structures and efficiencies, are more suited to an ELT structure; they cope well with the transformation work being done as pushdown workloads onto the data warehouse itself. This negates the need for the aforementioned tools, as each cloud provider generally has its own effective solution for the ‘EL’ side of ELT and loading data into the cloud data warehouses they natively support.
Enter the transformation tool!
In recent years, many of our customers have adopted specific data connector tools to handle the extraction of data from data sources and transformation tools to do the heavy lifting calculations within the data warehouse. Together, these ingestion and transformation steps form what many today would call a cloud data pipeline.
This has directly led to the increase in the usage of tools such as Fivetran to handle the former side of this solution, and dbt to handle the latter. But what if there was an alternative toolset that could handle the data ingestion side of your data pipelines, perform the heavy-duty transformations required, and orchestrate this effectively without bringing in more tooling, such as Apache Airflow DAGs to handle your transformation jobs?
Intro to Ascend.io
![]()
Ascend.io is a large player in Data Pipeline Automation for building the world's most intelligent data pipelines.
Ascend is a single platform that detects and propagates change across your ecosystem, ensures data accuracy, and quantifies the cost of your data products. This ultimately allows you to manage and build an ingestion pipeline, perform complex transformations, and orchestrate these as part of a more comprehensive business pipeline from one place!
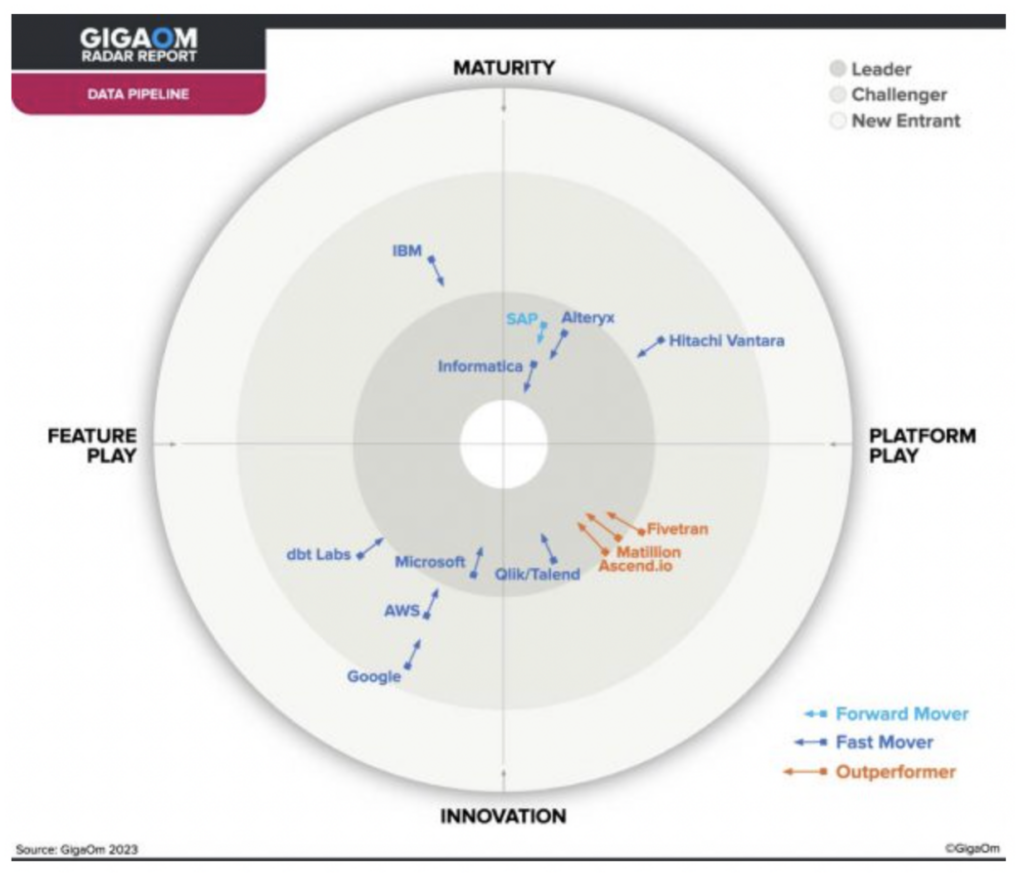
Ascend has been identified by a recent GigaOm report as one of just three outperformers in the Data Pipeline space, making it an ideal choice for a modern data pipeline.
The Ascend.io service detects any changes from your sources and propagates those automatically through your data pipeline via your Data Warehouse of choice, removing any of the manual scheduling or running of jobs for your teams.
It also provides best-in-class integration with various Data Warehouse providers via table/view optimizations such as partitioning within the Ascend dataflows themselves, optimizing how data is handled throughout your pipelines in Ascend.
The Ascend data pipeline service, when used to the fullest extent, contains 3 main planes:
- The Build Plane - Think of the build plane as a single pane of glass to program all pipeline ingestion and transformation logic. You can also program pipelines within Ascend via backend code using its SDK and CLI. The UI visualizes all data lineage and monitors operations in real time.
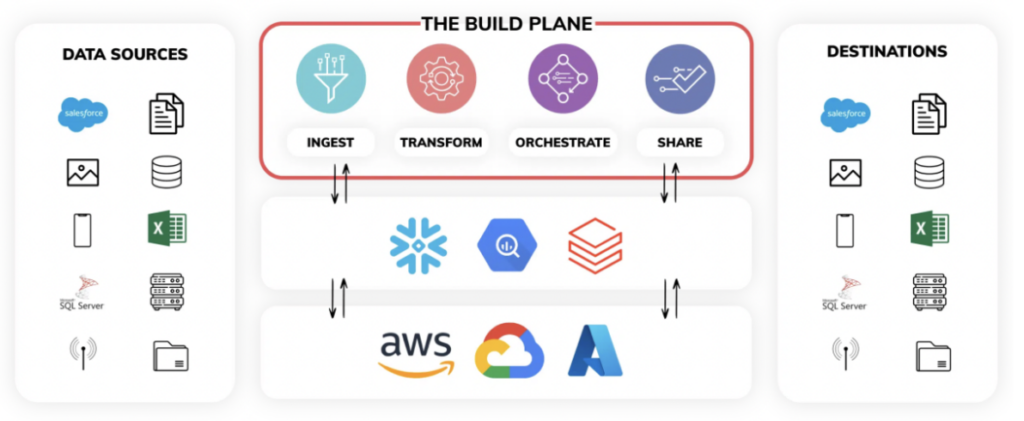
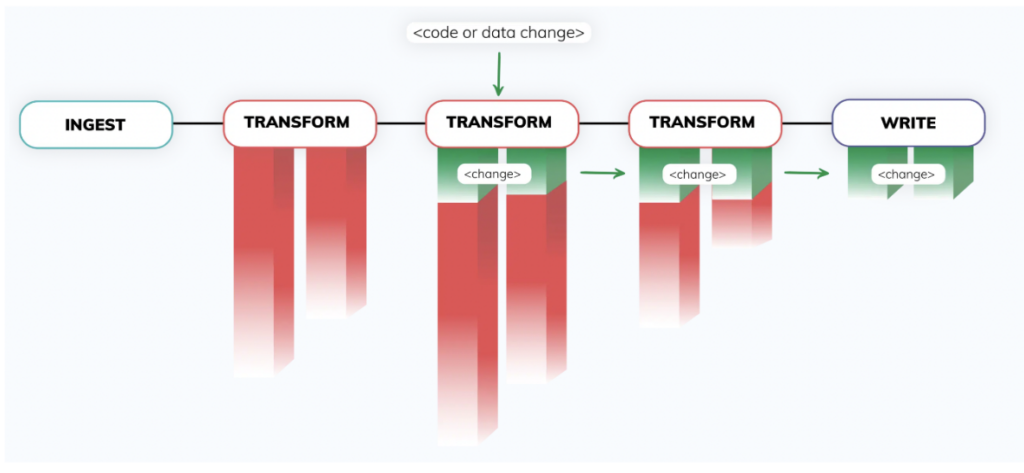
- The Control Plane - At the heart of the Ascend platform is a sophisticated control plane, powered by unique fingerprinting technology. This fully autonomous engine constantly detects changes in data and code across vast networks of the most complex data pipelines, and constantly responds to those changes in real-time. The data pipelines stay synchronized without any additional orchestration code.
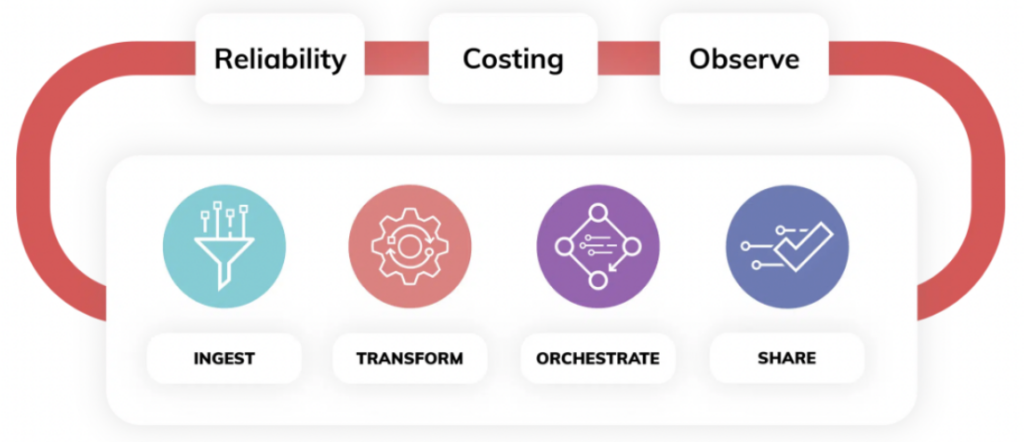
- The Ops Plane - Ascend’s ops plane helps integrate intelligent data pipelines into the business. It addresses three key data operations pillars: it raises business confidence, quantifies data processing costs, and creates transparency. The ops plane monitors the sequences of workloads in real-time, as the data is ingested and processed through the entire network of linked pipelines.
Ascend is currently compatible with Google BigQuery, Snowflake, and Databricks data clouds, with compatibility with other services continuing to grow in the near future.
This is definitely one service to consider strongly for cloud data pipeline workloads given its strong automation engine and ability to support both UI and code-based development. We’re excited to provide this deep dive on how to use it!
Intro to dbt
![]()
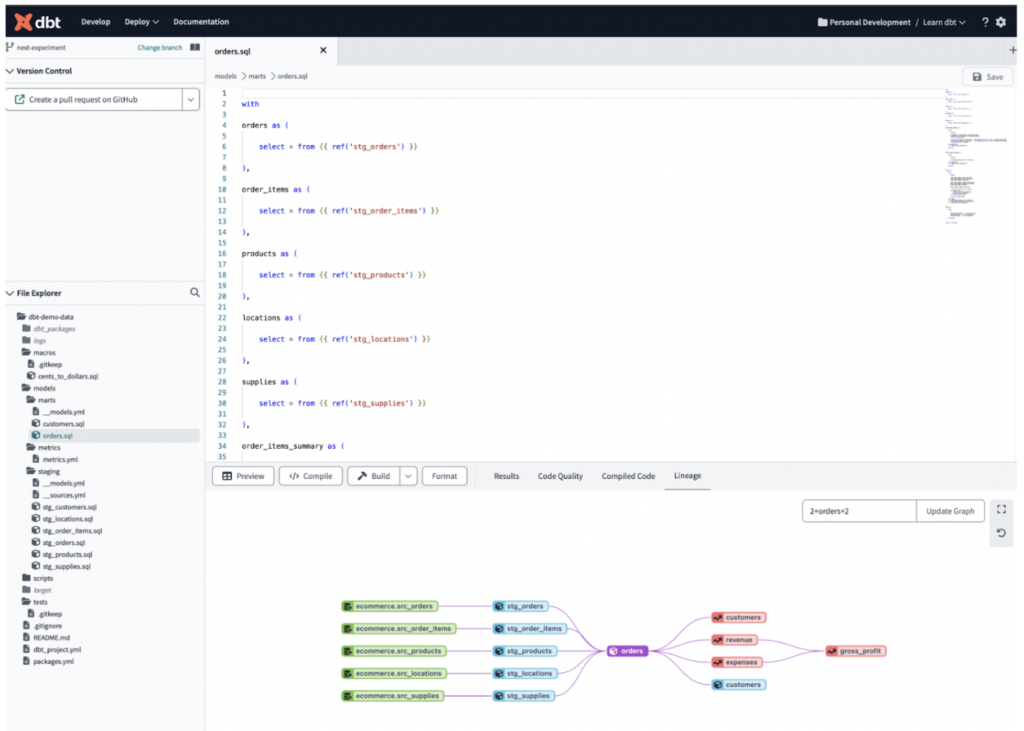
dbt is a SQL-based transformation pipeline tool that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. It allows teams to collaborate on development tasks via repositories and has been a really popular tool on the market in recent years.
dbt itself comes in two formats:
- The dbt Cloud service - a UI-based version of dbt that also handles the deployment and running of dbt models directly, this service has a free version for single-users and charges at different price ranges for teams of developers.
- dbt Core - this is dbt’s code-based version which is free to use and can be worked with via most IDEs such as Visual Studio Code, for example. Like dbt Cloud, it can also be linked with a repository of your choosing and can be orchestrated together with tools such as Apache Airflow to coordinate your data pipelines.
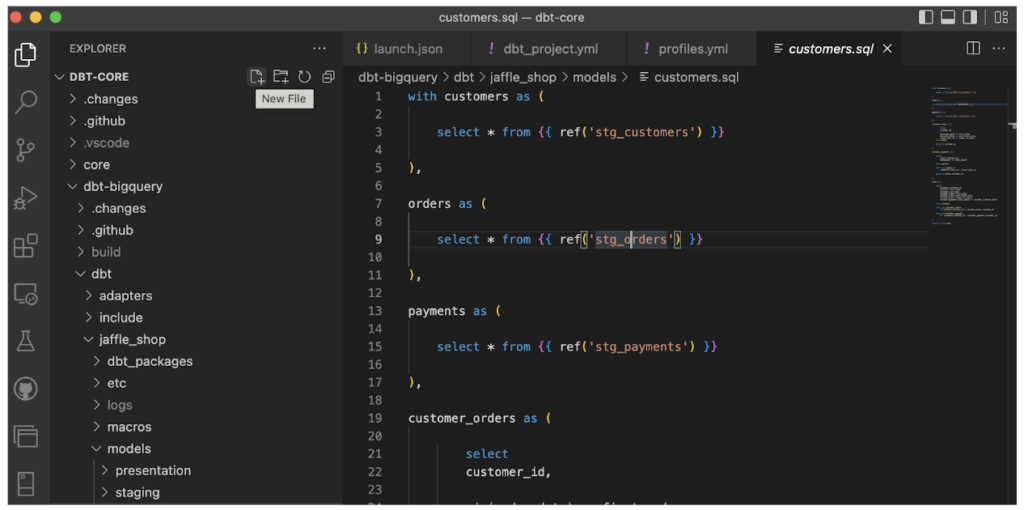
As well as coordinating the development and deployment of various transformation jobs, dbt allows you to perform unit tests on your data and also provides data lineage via its cataloging features, meaning that documenting the end-to-end flow of your ELT pipelines is made much easier!
dbt is compatible with various Data Warehousing and Data Lake offerings including Snowflake, BigQuery, Redshift, Databricks & Starburst, making it a popular choice for larger enterprises utilizing a variety of these.
The DoiT Bake-Off: Our Evaluation
So Ascend & dbt are clearly both effective tools for data transformation and both have their own contrasting advantages inherently, but which is better suited for a common data pipeline use case?? We have taken the following steps to perform a bake-off between the two services.
Our scenario: the bulk collection and transformation of daily weather data for the month of August with millions of records ingested from Google Cloud Storage, then run through data pipelines in both Snowflake and Google BigQuery separately in both Ascend.io & dbt Cloud.
Our pseudo pipeline will consist of the following standard steps:
- Reading the raw daily weather data from our Data Warehouse of choice and combining multiple daily extracts into a single table for further analysis.
- Segmenting this data into different categories (for hot, lukewarm, and cold weather respectively) - performing basic transformations on the combined dataset to achieve this.
- Performing more advanced aggregation and statistical transformations on the split datasets. As well as joining our transformed data onto a locations lookup table containing location codes for our weather areas.
- Outputting the final datasets into a pseudo-data mart/presentation layer in our data warehouses of choice.
In our case, we first want to compare the time it takes to build such processes from a developer’s perspective in both Ascend.io and dbt, as a key variable for your team’s performance is the amount of time spent building your data solutions.
Once the jobs are built, we then want to test the following areas for our assessment of the bake-off and total cost of ownership for each solution:
- The runtimes of the entire set of data pipelines from start to finish (using both hot and cold starts for Ascend’s pipeline due to the underlying Spark infrastructure involved)
- The credits used (for Snowflake) and bytes scanned (for BigQuery) in both data pipelines
- The error handling - we will introduce failures into both pipelines and investigate the recovery solutions for both
- The introduction of new weather data files into the data pipelines and resulting re-run to update the datasets, in order to test the performance of the respective pipelines when new data is ingested
- The level of interaction with and control over the underlying Data Warehouses - i.e. stopping Virtual Warehouses in Snowflake, automatic partitioning within Ascend jobs, and many other common pipeline orchestration tasks
So now we’ve set our terms of engagement for this bake-off, let’s develop our bake-off scenario and see how our weather data is enriched in both solutions!
The DoiT Bake-Off: Putting Our Case Together
Let’s walk through the development process from both the Ascend & dbt sides.
For our case study, we gathered the weather data from Google’s public ghcn_d datasets.
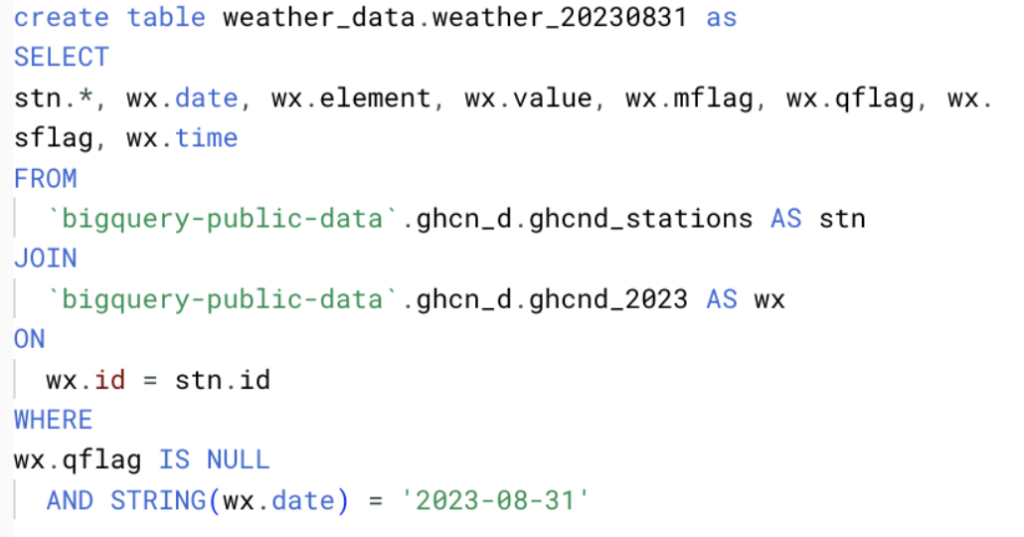
For the purpose of data volume, we selected all fields from this data and created daily files between August 1 - August 31 2023 inclusive, as per the below query.
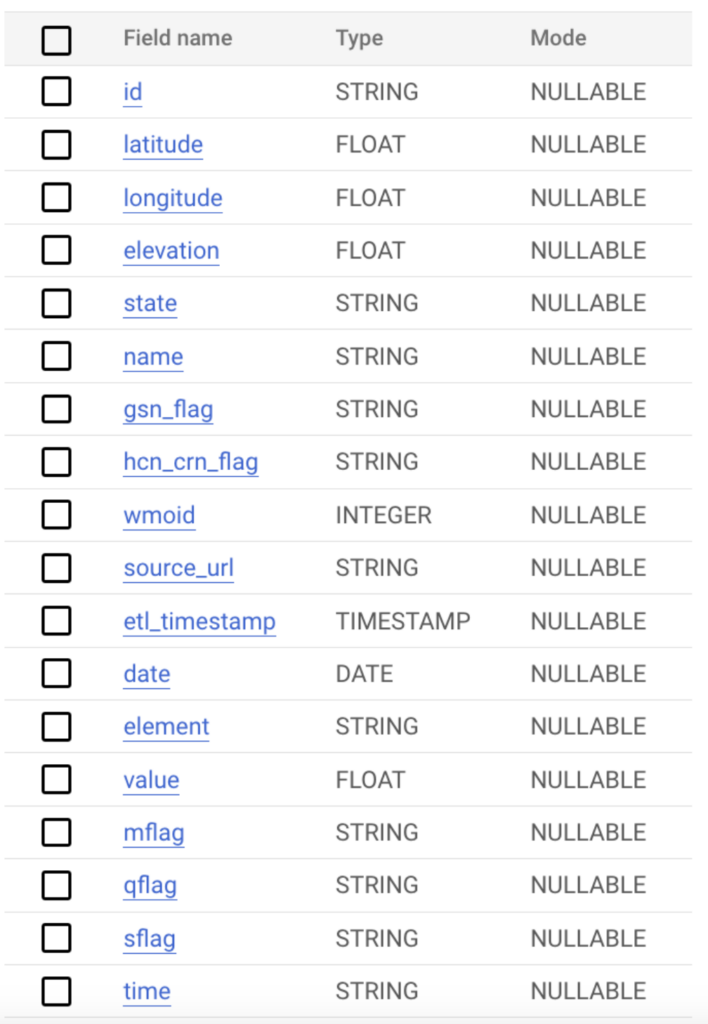
The data in this case has the below schema and millions of records in total. To test multiple scenarios, we have stored this data in BigQuery tables and Google Cloud Storage to test a variety of ingestion methods for the data across the platforms.
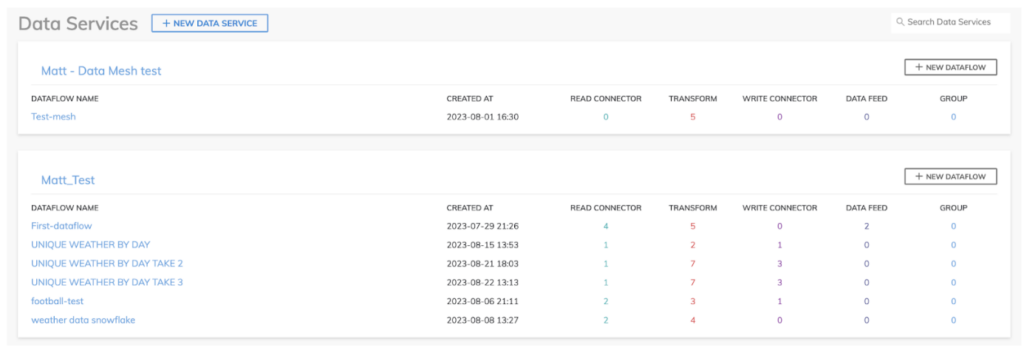
Ascend Development Process
In Ascend.io, you can create a data pipeline by creating Dataflows, these are in turn stored within Data Services which gives you a shared security model for your different data pipelines, as you can see in our playground environment.
Ascend’s Dataflows give you various ingest/read, transform, and deliver/write components that you can use in each step of your pipeline.
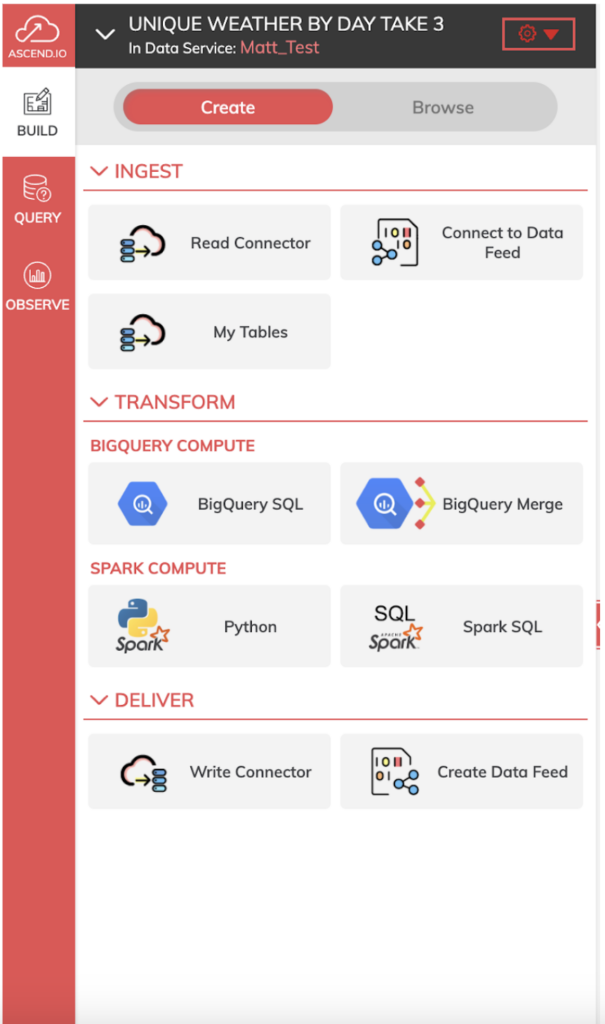
For our pipeline, we want to first use Read Components to ingest our initial weather data files from either GCS or BigQuery directly.
We then want to use transform components to shape our data for our process. I used BigQuery SQL for this bake-off as it is my most familiar SQL flavor, but you have the choice of a variety of languages such as Python, Spark SQL, or SnowSQL (if enabled) to build your transforms in Ascend.
Finally, we want to use a write component to write the output of our fully transformed pipeline back into our data warehouse of choice.
The pipeline pictured below is the one I built up for this bake-off. It is made up of three data routes for varying degrees of hot/cold weather scenarios for our final analysis:
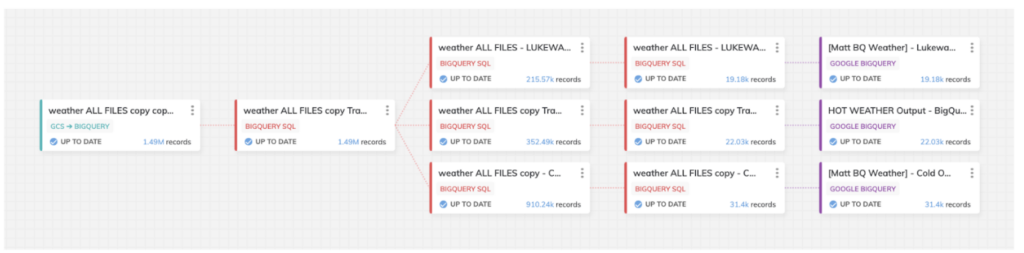
The design of this pipeline was the same in either BigQuery or Snowflake, but the screenshot taken is from the BigQuery-designed template.
For our read connector, we first wanted to set up our connection to the files in our GCS (Google Cloud Storage) bucket. For this, we needed to use a service account with access to the bucket in question.
As we have multiple weather files, we can specify a prefix for those in Ascend so that it knows to ingest all files with similar naming conventions for our pipeline.
We also ingested header rows into our CSV files, so we need to specify the option to exclude those within Ascend’s read component.
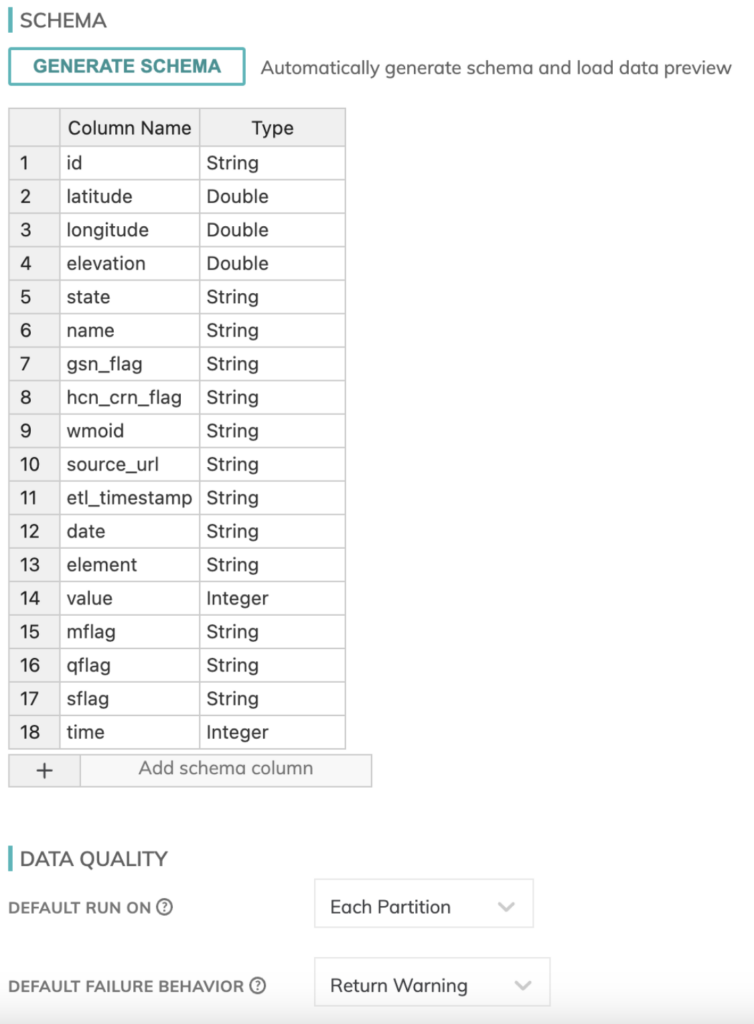
We also need to define a schema for our weather data. Luckily, Ascend has an in-built schema detector for the read components so this was fairly simple to put together.
You can also define data quality checks and failure behavior characteristics here for managing your jobs from start to finish.
Another interesting function that the Ascend platform offers is pipeline-specific dataset partitioning. This segments your data into meaningful chunks and processes them independently, speeding up the throughput of your data pipelines within your data warehouse of choice.

As you can see from a 20-day subset of our data, the partitions are segmented into one for each day of our weather files.
In terms of our transforms, setting those up in Ascend was simple as well. All you need to do is specify your language of choice and write the code in the main window of the component, as illustrated below.
One thing to note here is that similar to dbt’s macro language, Ascend uses Jinja logic to specify component names from previous steps of your pipeline. Developers familiar with this style will be at home with either platform.
To spare the length of this section, I've added one basic transformation component here for illustration purposes. But do note that we’ve added a full reference guide to the transformations built for this sample pipeline into a GitHub repository for reference that is linked at the bottom of this post.
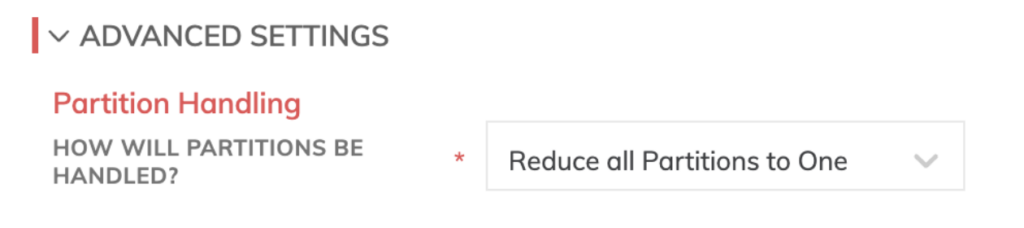
Finally, for our write or “reverse-ETL” components, we again needed to specify a connection into our BigQuery data warehouse.
Our connections can be set up within the Admin area in Ascend.io as seen here. These are vital for both read and write components and Ascend.io supports a variety of connections, such as Snowflake or BigQuery data warehouses or storage buckets in any cloud.
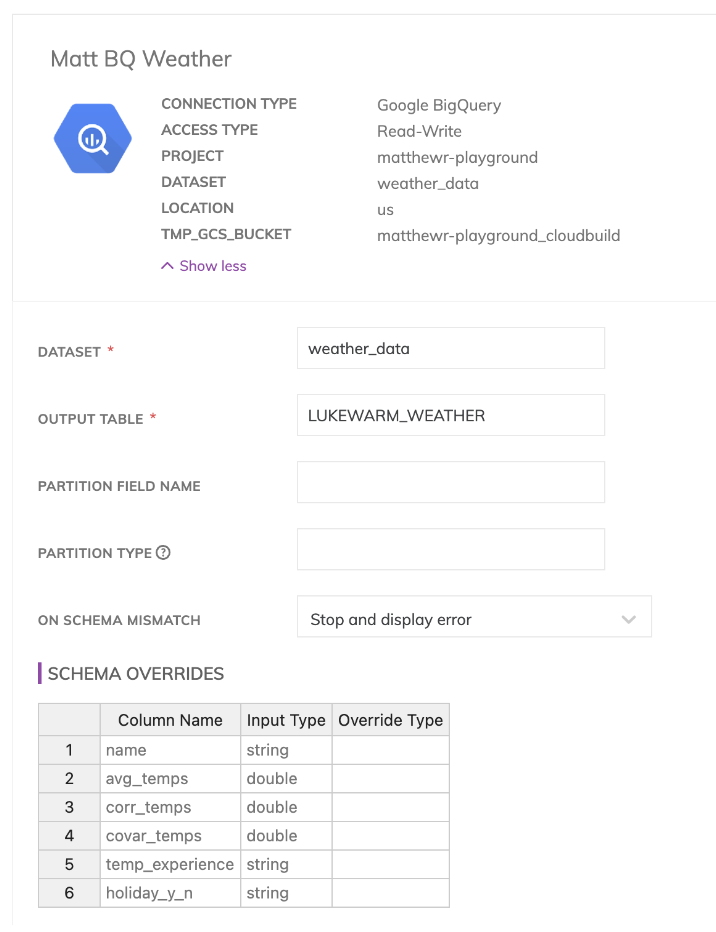
From there, our write components are fairly simple. You just need to specify a connection, your output schema layout, then for your data warehouse of choice your output table name, and any further cloud-specific options (such as dataset name in BigQuery or schema in Snowflake).
Take note that Ascend works by materializing the data at each transformation step of the pipeline in the Snowflake or BigQuery dataplanes by default. Hence the need to create an output connector back into the data warehouse is not required, but is available should you want to make any final adjustments to schema that don’t involve other transformation logic.
In terms of overall development effort, despite what seems to be several steps in my process and explanation here, this pipeline took me approximately 10 minutes to build in full and includes the time taken to set up my connections to GCS, BigQuery & Snowflake in my Ascend.io playground accounts for this demo.
It is worth noting here that whenever new Weather files were added as per our original terms of engagement, these were picked up automatically by our Ascend data service and the pipeline was able to re-run at will upon the new files/data additions.
The great thing about Ascend for this type of use case is that now my pipeline is set up and is fairly low maintenance for the remainder of its lifecycle. It really does not need a lot of additional work to either change logic or add new steps to my process. When these changes happen, the automation controller detects them and automatically figures out what sections of the pipeline need to be rerun, and which partitions of the dataset are due for a refresh. More impressively, this can happen across a number of interconnected pipelines, meaning that my one model change will be automatically orchestrated by the service kicking off dozens of processing jobs and DAGs without me doing any work. This is a big plus point for the Ascend service!
dbt Development Process
For the dbt side of this bake-off, I used the dbt Cloud service via my free account. This seemed like the more natural option because dbt Cloud has its own built-in orchestration rather than requiring a third-party service like Airflow, providing a fairer comparison to the Ascend all-in-one experience.
Similar to Ascend, in dbt Cloud you need to specify your development environment. As dbt is designed to connect to your data warehouse of choice, we needed to create connections for both our BigQuery and Snowflake environments, with credentials needed as shown below.
dbt itself has various directories that make up the infrastructure of its pipelines, including Models (containing SQL jobs executed in your DWH of choice), Tests (containing unit tests against said models), Macros (containing repeatable logic for your jobs) & Seeds amongst others.
For the purposes of this pipeline, we baked in the identical logic from our Ascend pipeline into dbt in the form of various .sql model files to replicate the same process.
Below is a view of the DAG for our built dbt process for the bake-off logic:

In this case, to replicate the ingestion & combination of the CSV files we get from Ascend read connectors, the “stg_weather_data” model in dbt combined the many source files/tables together using external source logic in the case of GCS or used wildcard logic from BigQuery to combine all of our data together into one file as in the Ascend equivalent job (as shown below).
This was able to handle the additional files added scenario mentioned in our terms of engagement, with the wildcard clause designed to pick those up as new files were loaded into BigQuery (or logic can be modified to pick up new files added into GCS).
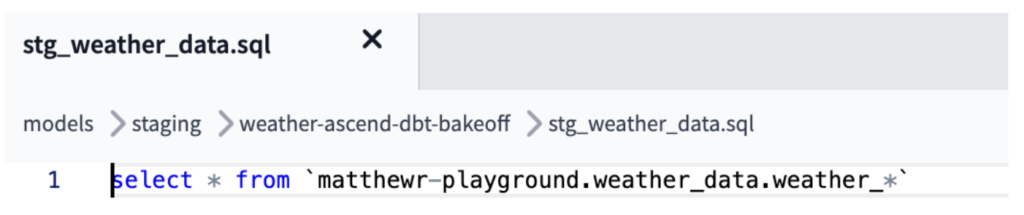
We then created various dbt models in different directories for Staging/Mart data warehousing layers, with the final mart table used in our example to output the equivalent table to our BigQuery or Snowflake data warehouses, respectively. This allows us to achieve the same results via the exact same SQL syntax as our runs in Ascend, for a true bake-off comparison.
Using dbt Cloud, we then deployed the dbt output as a job, which was used to orchestrate the dbt pipeline run as illustrated.
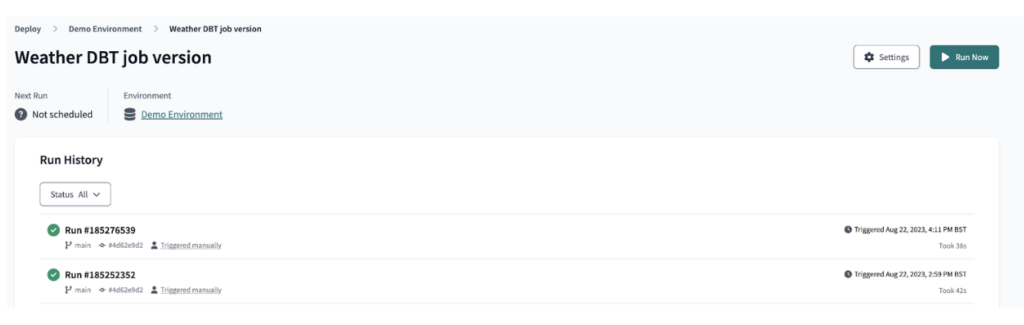
As a consequence of configuring the orchestration of the dbt cloud job, we found total development time to be slightly longer than the equivalent Ascend pipeline build. Also, with dbt being a code-based solution, additional time was also needed to configure the standard ingestion side of the pipeline (via .yml file configuration) and the output of the final presentation layer table, which was baked into the write connector for the Ascend pipeline.
This equivalent pipeline took around 20 mins or so to build in dbt.
It should also be noted here that, unlike Ascend, dbt does not have automated measures to split your data into partitions on ingestion. It also lacks the ability to detect additional files added to your source bucket and kick off new incremental batch ingestions shortly after they are detected (whether in GCS or BigQuery).
You can apply BigQuery partitioning and clustering in your dbt .yml files, but this requires additional configuration and is not the equivalent of the ingestion partitions created automatically in the Ascend tool.
Additionally, while dbt error handling logic is supported through various packages such as Great Expectations, this is again something you need to configure via the installation of those packages. A macro knowledge of the syntax of these packages is also required to add this logic for your jobs, rather than a simple set of checkbox settings as provided in Ascend.
The DoiT Bake-Off: Results
And now the moment we’ve all been waiting for. Let’s bake!
Our tests of both pipelines from start to finish gave us the following performance results:
Runtimes
“Cold Start” - average first runtimes of full pipelines
- Ascend: 2 mins 6 seconds
- dbt: 47 seconds
From the broad initial runtimes, we can see that the dbt Cloud pipeline was faster on the cold-start run of our pipeline. But this is likely affected by the infrastructure of the Ascend pipelines under the hood, where Kubernetes clusters are spun up on the fly to handle the job execution and idled between jobs to reduce compute costs.
So we did another runtime check to do an apples-to-apples comparison of a hot-start scenario when the Ascend clusters had already been spun up.
“Hot Start” - subsequent average runtime of full pipelines
- Ascend: 10 seconds
- dbt: 32 seconds
Our subsequent runs of the pipelines showed Ascend to be much faster with the same data volumes and transformation code running in both pipelines. This is likely due to the dynamic and parallelized nature of the Ascend clusters, meaning that processing for the individual steps can be multi-threaded and significantly reduced as a result.
Snowflake Credits used & BigQuery Bytes comparisons
Snowflake credits per job
In terms of the Credits used throughout the full pipelines for both Ascend and dbt, we segmented each of them to use different schemas across our Snowflake Database for the bake-off. Namely, the Ascend pipeline used the “sources_ascend” and “ascend_t_conn” connections, while the dbt pipeline used the “dbt_mrichardson” and “public” schemas.
The Ascend pipeline was noticeably more efficient than the dbt pipeline regarding Snowflake credits used. The total amount of credits used were:
- Ascend Pipeline Consumption = 61.165 + 28.071 = 89.236 credits
- dbt Pipeline Consumption = 1924.652 + 33.685 = 1958.337 credits

This wide gap from a Snowflake perspective is likely due in part to the partitioning capabilities that Ascend performed on our weather data. Because each file was propagated incrementally without requiring a full reduction at ingestion, far less compute was needed to run the pipeline and similarly during its development. The gap can also be attributed to other cost-saving and compute management features of the Ascend platform, such as switching off Snowflake Virtual Warehouses as soon as the pipeline finishes processing to avoid accruing unnecessary up-time.
BigQuery slots used per job
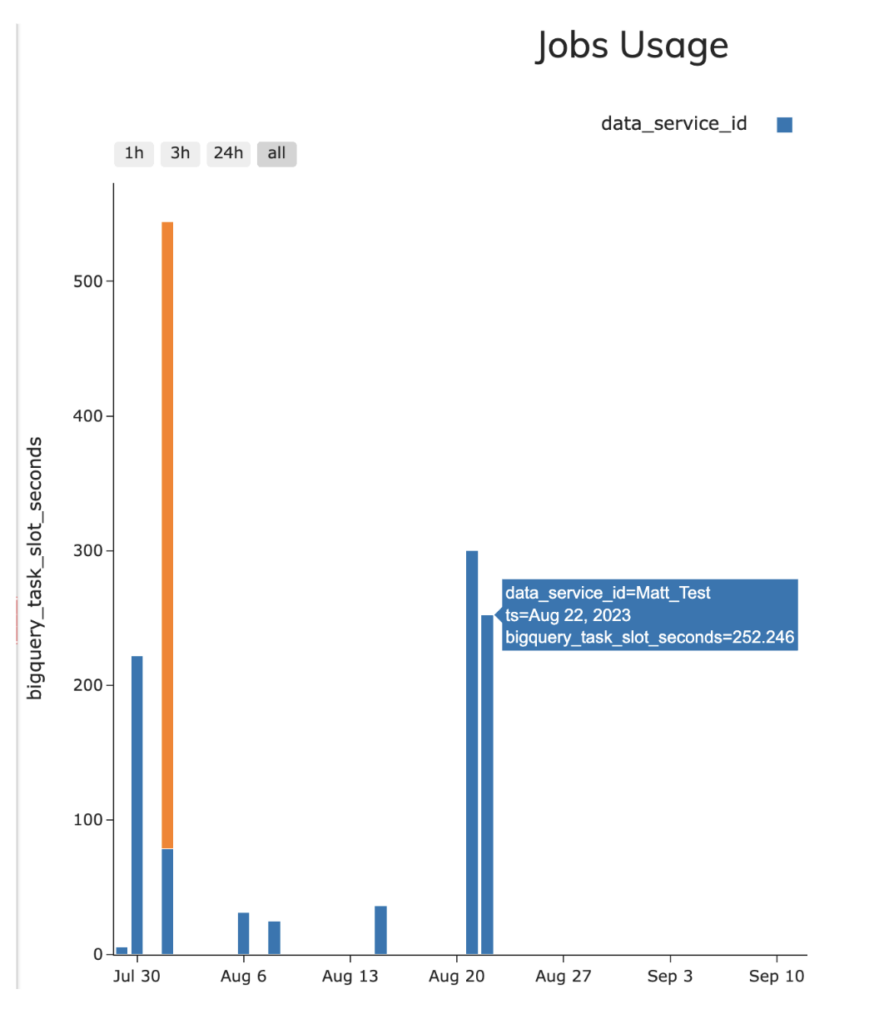
- Ascend - 4.18 average slots per second (252.46 total slot seconds)
- dbt - 3.2 average slots per second (189.34 total slot seconds)
On the BigQuery front, we found that both pipelines were able to execute the BigQuery jobs fairly effectively from a slots perspective, with dbt Cloud being slightly more efficient on average throughout the job execution. Upon looking at the reasoning behind this slight difference in slot utilization, this was caused by the nature of my Data Service run settings in Ascend vs my test DAG built in dbt in terms of the parallelism of either run, with the former running more of the steps for my pseudo ETL process in parallel leading to higher slot contention in Ascend vs dbt in my basic example (due to the threads allocation in my dbt configuration).
To test, I tweaked my dbt pipeline run by adding the –threads:4 option to expand the parallelism of my dbt pipeline and then saw a very similar slots per second average performance of around 4.3 slots per second due to the slightly larger contention for slot resources when my pipeline re-ran.
To check those stats I used the information_schema sample query from the JOBS view to test both pipelines (included in the accompanying GitHub repo), however it is worth noting that on the Ascend interface, the below view is included in the tool for measuring BQ Slots utilization and Snowflake Credit consumption for Ascend-run pipelines as per the below screenshot.
Error Handling Scenarios
We also tested for a couple of error handling scenarios across the two pipelines, namely:
- Pipelines stopped at 70% of load points into the pipeline and also part-way through transformations by introducing errors that simulated normal bugs in the code or ingested data. We then attempted to restart the pipeline from this failure and see what happened.
- Adding a new erroneous CSV file to the pipelines to deliberately trip them up.
We found the following when testing out these scenarios directly.
Ascend Error Handling
- Both the scenarios of failing at 70% point through a pipeline run and when adding a new malformed CSV file to the bucket failed gracefully. Ascend provides us with advanced settings to control the pipeline behaviors when such errors occur in our pipelines.Ascend’s recovery from a failure was far more graceful as well. Because of the materialization of each pipeline stage, it was able to simple resume from the last complete component and restart right from the point of failure. This saved a significant amount of recompute that would have been required if the pipeline would need to be rerun in full.
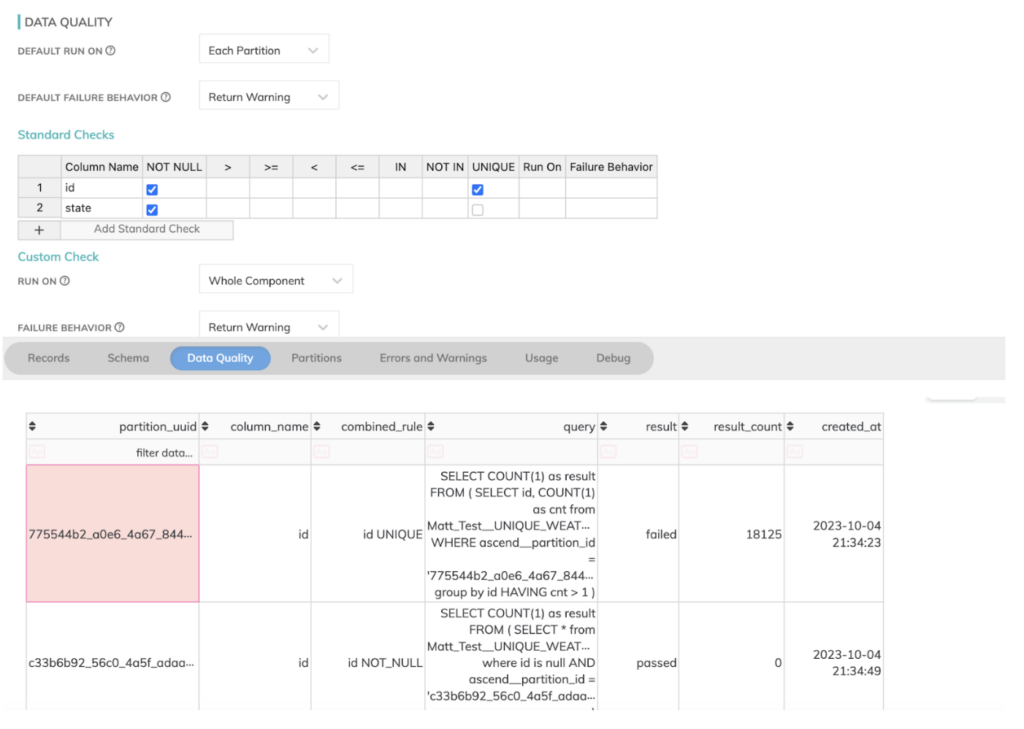
- Furthermore, similar to dbt, Ascend.io also provides data quality checks that are useful for detecting the issues in our bad CSV files and preventing them from entering the system. This is all built under the hood and requires very little additional configuration to take advantage of, as shown below from Ascend’s data quality tab where I’d inserted a few bad field values into our source data files.
dbt Error Handling
- The scenarios mentioned above weren’t as well suited to dbt. We could store/keep errors in an error-handling table similar to the Ascend pipeline. Still, these capabilities required the download of additional dbt packages (in particular, the dbt-expectations package provided by catalogia does provide good functionality on the data quality side it should be pointed out here). And while we were able to implement a restart process in our pipeline, this involved either a manual re-run of the jobs or additional error configuration added to dbt Cloud in the retry settings for our jobs.
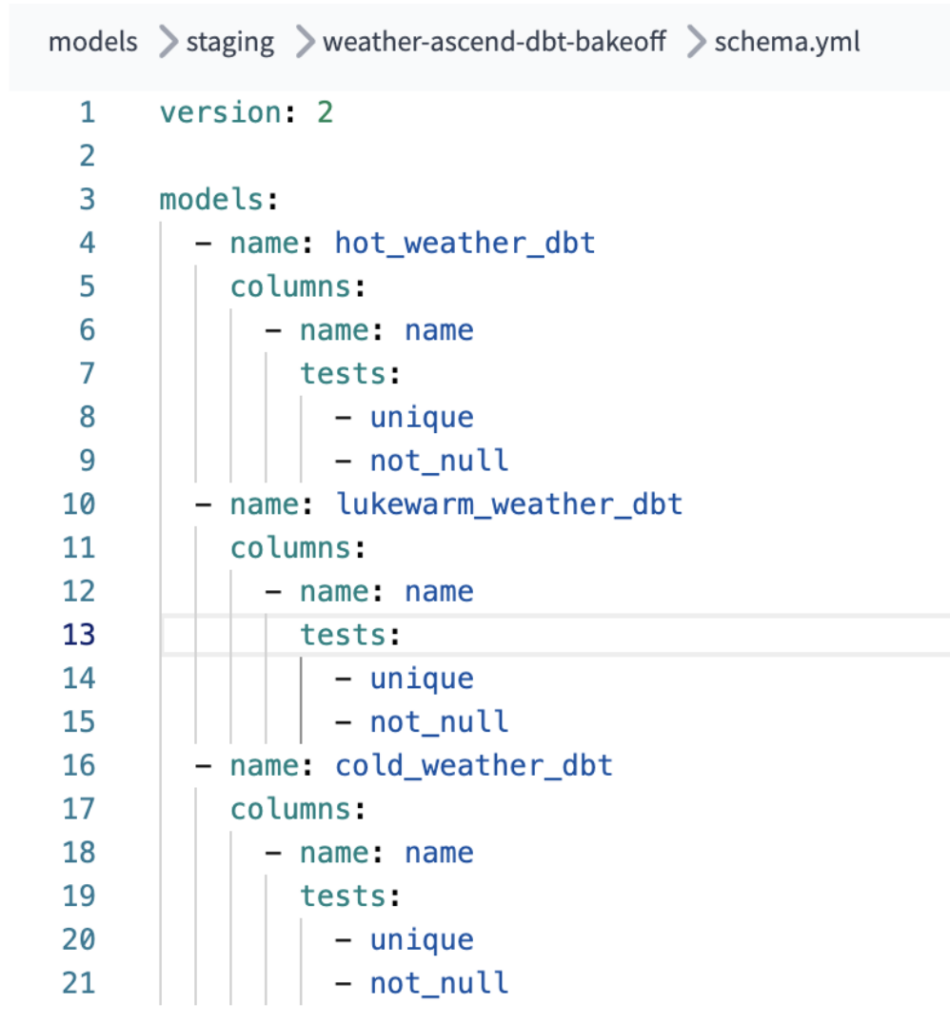
- Additional configuration to allow for not-null & unique tests for each of our dbt models was also required to get our dbt pipeline to perform those checks. This was not an excessive amount of additional effort but could trip up developers not as familiar or experienced with dbt Core / dbt Cloud project configuration.
Closing Observations
From our testing on our weather data case study in both Ascend.io and dbt, we can see clearly that both services can meet the needs of data transformation use cases. However, after extensive testing of both services' native features and third-party extensions, we can also see that the toolset for you depends on which set best suits your needs.
With Ascend.io, you have a one-stop cloud data pipeline tool that optimizes and orchestrates your data pipelines automatically under the hood. It has a more friendly UI to make pipeline creation simple and efficient for developers of different experience levels. It includes performance enhancement techniques to make your pipelines run flawlessly without an expert level of data infrastructure knowledge or hours of manual coding required.
We feel that Ascend.io is certainly worth a trial for your cloud data pipeline needs, particularly where your data management processes would benefit from less maintenance and fewer orchestration tools to manage. Its simplicity in job setup and cloud compute cost reduction settings out of the box make the Ascend service a great alternative to more code-focused tools such as dbt, depending on your use case.
For reference from this article, the pipelines built in Ascend and dbt can be referred to from the Github repository here.