Several years ago I set out to learn more about AI and machine learning (ML) and how I could apply it at my own companies, or at least speak intelligently with our data science and engineering teams.
I took online courses, watched videos, and passed exams but did not feel like I really understood how to apply and integrate machine learning into my business. So many questions were left unanswered. If this sounds familiar, read on.
Demo
To inspire you to read this article and part 2 of this series, please sit back and first watch this demo of a working machine learning pipeline.
Most describe an ML pipeline as the series of steps to organize and refine data, use the data for training machine learning models, and then serve, or use, those models within some application. Don’t worry if these terms don’t make sense yet.
This demo creates its own structured data from user input, so it simplifies the process for easier understanding — at least I hope so. I’ll share the source code and approach to designing and building it in my next article.
Bridging the ML vocabulary gap
Most people like me with a software engineering or product background speak a familiar language with terms like class, method, function, parameter, input, request, variable, loop, output, return, and response.
In the machine learning world, there are analogous terms like observation, model, dimension, feature, fit, train, test, and inference. Add in mathematical Greek symbols like theta and your head begins to spin. It can be overwhelming at first but we will ease into learning these terms as we go.
In its simplest form, a machine learning model is a math function that when given numerical inputs, returns a numerical output.
I believe a problem with current teachings is it takes too long to understand how to use the technology so we’ll begin with these questions:
- How do I use this function in real life (a.k.a. serving)?
- How do I create this function (a.k.a. training)?
- What techniques are best for certain problems?
TL;DR
Let’s get right to it, learning these answers in the reverse order that most teach.
1. Serving your models (using your function in an app)
Machine learning models, a.k.a. functions, are stored in files. Software libraries can open and run them, accept inputs, and return results.
Think of these model files like mini “spreadsheets”. They have some some cells with formulas. When you pass your input to the “spreadsheet” it places your values in cells (like yellow cells below) and computes a return value which is your prediction (like green cell below).
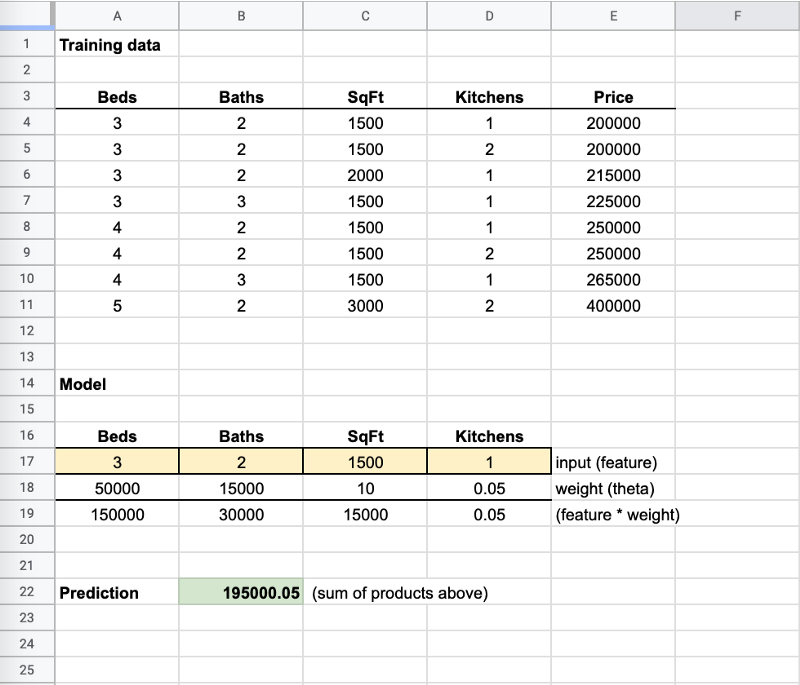
Notice in my training data (we’ll discuss more below) that whether I had 1 kitchen or 2 kitchens it didn’t change the price. The weight (multiplier) therefore is nearly 0 because it isn’t an important feature to determine price.
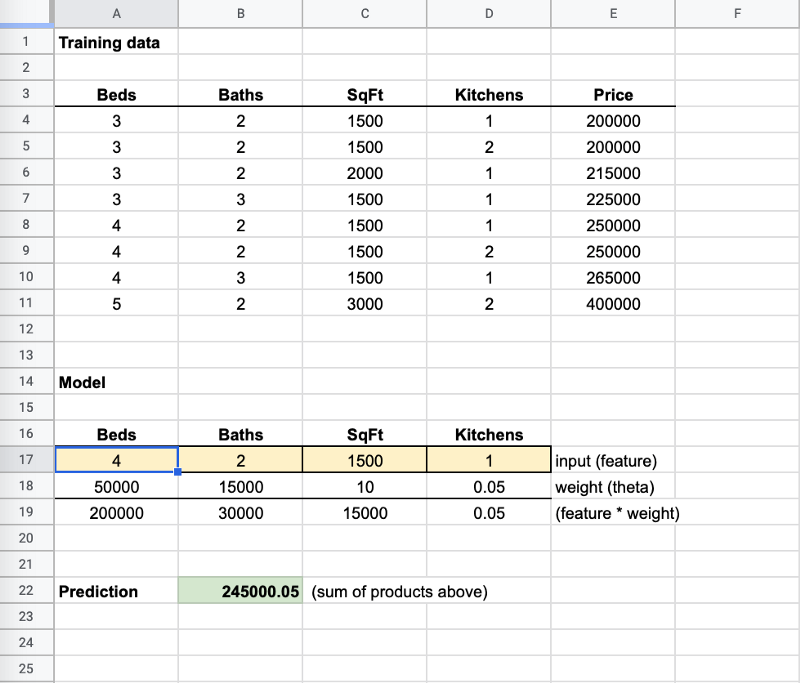
Now when I changed the “Beds” to “4”, the prediction got close to the 250,000 value. The ML algorithms adjust the weights to tiny fractions to get them as close to accurate for all inputs as possible. Thus it’s very rare to have 100% accuracy.
A popular model file format is called pickle, and a tool to create and run them is called joblib. Other frameworks like TensorFlow and PyTorch have their own formats, and there are attempts at universal formats to make models more portable.
To use your model in your application (serving) as illustrated above, you import the compatible library version used to create the file, load() it, then predict() just like any other function in your software programs. I will share a working example later but that’s really it!
2. Training your models (building your function)
We’ll get into more detail later, but assume you wanted an input of food and predict whether your child will like it; we all know where this is going! ;-)
Traditionally you would write a function by hand like this with known rules:
Your inputs (features) may be attributes about the food like type, smell, spice, temperature, sugar content, or color. Your predicted output (inference) is either “good” or “bad”.
The problem manually writing your function above is whether you really know what the ideal temperature, sweetness, or smell is and which factors are most important to a child deciding whether it’s “good” or “bad”. This approach is trial and error at best.
Now imagine the data you have is ten thousand records. Your brain cannot possibly remember and correlate all those values to determine where that cutoff point for spice level, temperature, smell, and sweetness is. If you use a computer and pass in all that data, it can figure it out, typically within seconds, and define a math function that will return the correct predictions. That’s what machine learning helps us with.
Let’s keep it simple for now with the code below:
This is a simplistic example to “demystify” what machine learning is. Instead of writing the function and rules yourself, you use an algorithm that iteratively multiplies different weights to each input value until it returns the correct answers most of the time (remember the spreadsheet above).
Assume you input 100 records and a pattern emerged that every time the color of the food was 4, the result was 0 (“bad”). The function begins to write itself as it discovers these rules, just like your manual function had rules in it. The response (inference) is mostly correct because you created the function (trained your model) based on some data you already had with correct answers (labels).
Imagine a month later your child says they like broccoli. It’s green, so you have to figure out how to rewrite your first function to account for it. As data changes, this gets harder and harder. By using machine learning, you simply feed in the new information and retrain your model until it has accurate predictions. That is the power it offers.
3. What techniques are best for certain problems?
We are going to skip this. Most AI courses begin with categories of ML algorithms and I think it complicates the learning process. For now, ignore it. First, gain an understanding and later enhance your knowledge.
Recap on what we learned so far
What I hope you understand is that you can manually create a function like above, and guess at constraints like “if a vegetable it’s bad” and potentially gets accurate results.
As the type of prediction gets more complicated, speed is critical, or as there are more data points to consider, it surpasses the ability to safely guess in your head and that is where machine learning can assist.
Terminology
- Model — a math function generated by a computer program that applies unique weights to numerical input values and returns a numerical result.
- Feature — a numerical input value or parameter (a.k.a. dimension) you pass to your function for it to return a prediction.
- Label — a known answer for past data (a.k.a. class) like in our child food tastes we already knew they liked pizza and cake and not spinach, so we gave pizza and cake a value of 1 for good, and spinach a value of 0 for bad.
- Observation — a set of features gathered about a particular input like the features we extracted from pizza.
- Feature engineering — identifying the attributes about a given observation that likely influence the result and converting them to number values so you can build a mathematical function instead of a manually-written one like we converted colors and food types to numbers by referencing their array index instead of string value (a.k.a. feature extraction).
- Training — repeatedly iterating through a data set, trying out different weights (theta) on each feature until most results are correct.
- Fit — behind the scenes your ML algorithm is trying to figure out the coordinates of a line that can separate “good” from “bad” records so future records that plot on one side of the line are “good” and ones that plot on the other side are “bad”. This is effectively what training is doing but don’t worry about it right now.
- Inference — technically this is the “act of predicting” but for sake of clarity just consider this the result, or prediction, that is returned by your model function (i.e. — given these parameters, I infer this answer).
- Serving — using your function in a program by loading the model file and passing it parameters so it can return predictions.
- Testing — passing in test features to model to get predictions, and then comparing result to known values (labels) for a group of records.
- Accuracy — the percentage of prediction results that matched the expected result out of all test records. Future terms to research later: precision and recall.
Less important terms right now but they’ll come up in the future:
- Theta — the weight multiplied against each feature to return a prediction based on its perceived influence on the result. A good example is predicting home values. Perhaps a sale for a 3 bedroom home that has 2 kitchens is $200K. Another sale for 3 bedroom home with 1 kitchen is $200K. A sale for a 4 bedroom home is $250K. The model may give a higher theta (a.k.a. weight or importance) to the number of beds feature because it influences the price, and lower theta on a number of kitchens because it had little impact.
- Hyperparameter tuning — if you know certain features are more or less important to determining the outcome, you can apply your own weights during pre-processing or feature engineering steps to further improve the accuracy of your predictions. The goal is to minimize loss (a.k.a. penalty) for bad predictions so predictions are less sensitive to input variations. It’s geeky, I know, so ignore it for now.
Process
We learned that serving is using a software library that can read and execute your saved model file (i.e. joblib). If you had a web API and it accepted parameters like food type, spice, sweetness, etc. you could load() your model and pass in these parameters and it would predict() a 1 or 0. Your API interprets 1 = “good” and 0 = “bad” in your response to users.
We also learned that to train your model, you may need to perform feature engineering. This is where you identify values related to that food (observation) that may influence the outcome, and convert some to numbers so they can be fed into a math function. You then set aside some known (labeled) records for testing your accuracy, and train (fit) your model until accuracy improves.
Now let’s look at a practical application before diving into our actual implementation.
Applying machine learning to a business problem
I think it helps to explain things in terms people can relate to. Imagine you have a website and you want more subscribers (to sign up for something). In the past, you spent equal amounts on Google, Facebook, television, radio, and print. You have the same budget for advertising in the next year and need to know where best to spend your money to increase net new subscribers by twenty percent.
You need to figure out what percent of your advertising spend to allocate to each provider to have the most new subscribers.
You’ve analyzed your new subscribers each month from last year, and the source with respective cost and sign up counts. You discovered that most subscribers came from Google, then Facebook, then television, and a few from radio and print but the amounts vary by season, or even by month.
If I spent different amounts than last year with these same providers, could I have signed up more subscribers?
Have you ever used ‘Goal Seek’ in Excel?
Traditionally your attempt to optimize the allocation of the budget may have started with a guess or theory, then perhaps some simulations in a spreadsheet. You paste in last year’s results and each row has the amount you spent on each provider and how many new subscribers each delivered at what cost, and possibly other data points you think might be important. You change these values, over and over, to see if you get a higher number of subscribers.
This is actually what the ‘Goal Seek’ feature built into Excel does automatically but few may use or even know about it. You set a goal like this example below, and it iteratively changes the amounts in other cells until it reaches the desired value in the output cell.
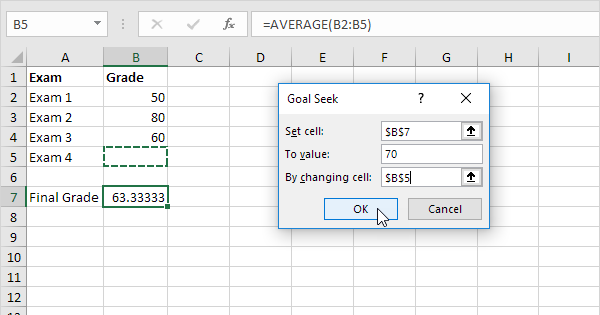
If you consider the advertising example, you are trying to find the relative importance of each type of advertising and allocate a percentage (or weight) of your total budget. You know how many subscribers you had last year and you want 20% more for the same budget.
You set this as your target value, and then you change the % spent on each provider until you achieve your goal. That’s how machine learning models are trained, iterating through data and changing values (weights multiplied against input parameters) until it gets closer to the known answers (labels).
Don’t worry if this doesn’t all make sense. As you explore the application and more in part 2, then revisit this part, things will begin to “click” (I hope).
Machine learning takes ‘Goal Seek’ to the next level
After a lot of trial and error, you find the correct mix (weight or percentage to each advertising type) to achieve your goal. Say that your data, however, includes 100 signups per day for 365 days of the year and different days resulted in more signups with one provider over another. It would be far too difficult to identify the differences of 36,500 rows of data with the provider, day of the week, day of the year, views, clicks, conversions, signups, cost per click or impression, etc.
Hopefully, it’s clear that some problems are just not suited for humans to solve and this is one of those functions, unlike your child’s food tastes, that is likely best to be automated. Machine learning algorithms are a lot like ‘Goal Seek’ but they can iteratively change the values in many cells at once and test each change until the output value gets closer to the known (label or class) for any given input.
Continue on to part 2 to see how the demo above was created and links to source code.