Wondering where to start when modeling your data in Google BigQuery? This post has you covered with a simple repo and example.

Today, a lot of ugly data glides across the ether. Usually, some very frustrated people wonder where to start making sense of this and, more importantly, how to structure it to be useful for their company.
Here I propose the usage of a simple script and repo that allows you to push your cleaned data as Views to Google BigQuery. In addition, you can use Jinja templating to make your life easier and even pre-define some variables if you like.
How does it work?
In a file called select_101.sql.j2 you can have this query:
SELECT {{aNumber}} as num
The template reference aNumber is taken from a pre-defined set of variables in a configuration file configuration.json :
{
"aNumber": 101 }
You also have a schema file called select_101.json :
{
"metric": "First example",
"metric_description": "Select only a constant number as output",
"purpose" : "",
"usage_example" : "",
"usage_description" : "",
"fields": [
{
"field": "num",
"description": "A small number",
"type": "INTEGER",
"typical_values": [ 4 ]
}
]
}
Now you are ready to deploy this to Google BigQuery:
-m allows you to provide a metric to deploy
-v indicates you want to deploy a view
-d takes your dataset as input
-p takes your projectId as input
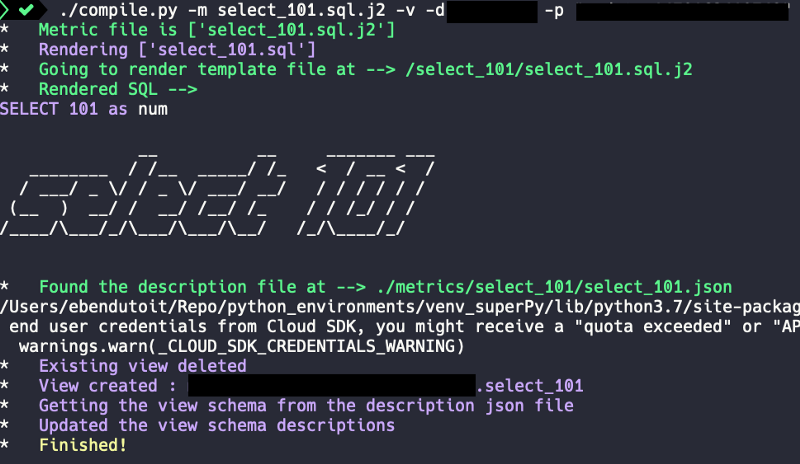
./compile.py -m select_101.sql.j2 -v -d <YOURDATASET> -p <YOURPROJECT>
And you get this output:
Including templates into templates…
You can also include templates in another.
In a file called select_101_include.sql.j2 you can have this query:
SELECT *
FROM (
{% include 'select_101/select_101.sql.j2' %}
)
The query will render and deploy as:
SELECT * FROM ( SELECT 101 as num )
Happy modeling!
Want more stories? Check our blog, or follow Eben on Twitter.