Alright! If you're here it probably means you have read Part 1 (The Why), and you want to know more about how to properly set up cloud-native developer environments. Great!
Let’s follow an example of an existing project team and how can we improve their development workflow.
This guide was written with GCP (Google Cloud Platform) in mind, but the same concepts can be applied to AWS as well.
📖 Case Study
A company called MajesticFantastic has a few payment-related products 💸
The billing project team owns the development of a billing application.
It is composed of the following:
- Few microservices deployed as containers in GKE 🛳
- GCP cloud services used: Pub/Sub, Cloud SQL (PostgreSQL), Cloud Monitoring, Container Registry.
- Current Environments: Dev, Prod.
- A team of 2 developers: David, and Martha. Pretty soon, a developer named Ezekiel, and a few more developers are expected to join the team since the company is in a fast-growing phase. Exciting times! 🚀
Proof Of Concept
We will introduce a new environment type. We will call it “the Personal environment”.
For the personal environment, our POC will consist of:
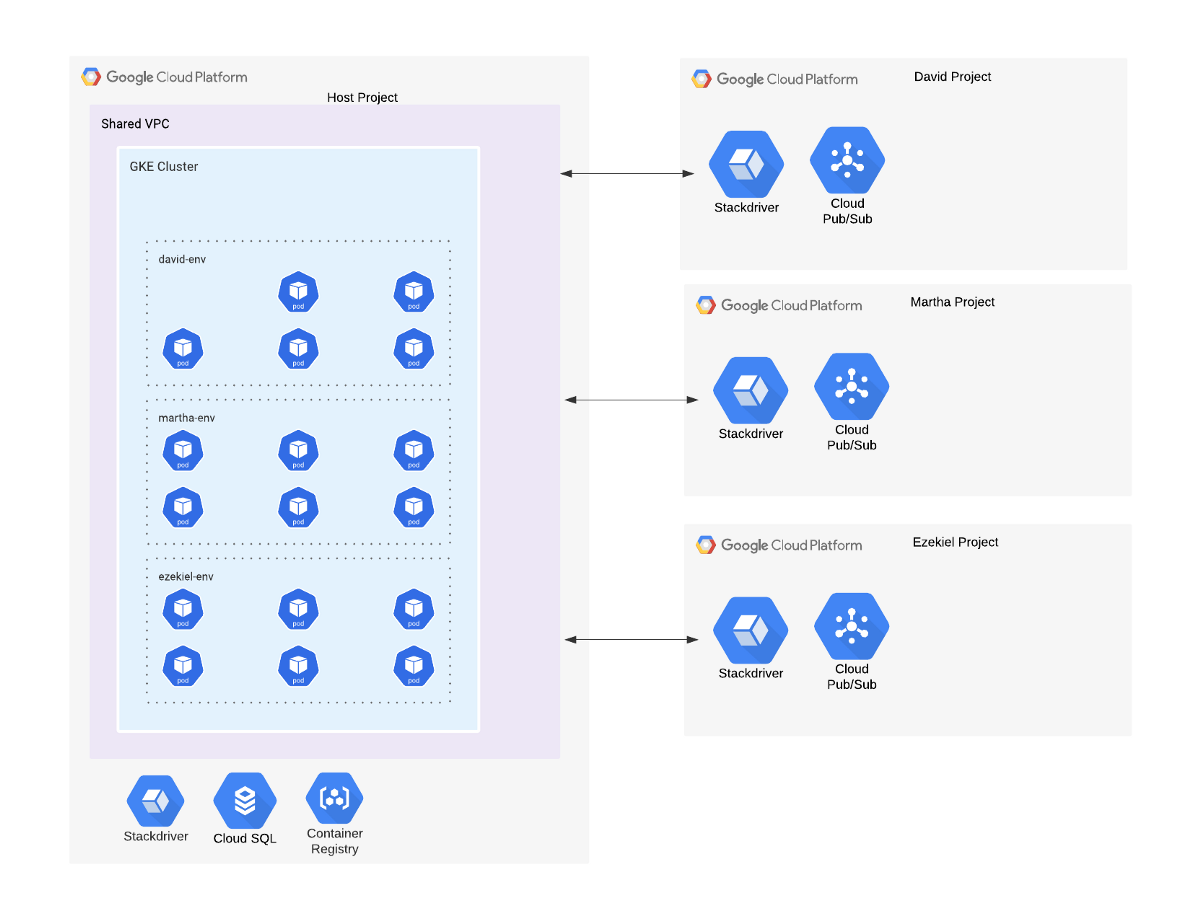
- A GCP project that will act as the Host project. This project will host the GKE cluster, the Cloud SQL instance, and the container images in GCR.
- Multiple GCP Personal Projects — one for each developer. Each project will hold non-shared resourced scoped per developer. For example, in our use case, it will host the Pub/Sub topics and subscriptions.
- A Shared VPC. Its host will be the Host project, and each Personal project will act as a Shared VPC service project.
GKE Cluster Multi-Tenant
We will allocate a K8s namespace per each environment (for example — David’s environment will get the david-env namespace, Martha will get martha-env, and so on).
Each environment shall solely access its own namespace, without relying on resources that reside on other environment's namespaces.
Note: We will not enforce anything security-wise for now. Security measure can take place, more on that at the end of this article.
Cloud SQL Multi-Tenant
Cloud SQL supports Users and Databases so we can allocate a User and a Database per environment (Note: we are using a single Cloud SQL instance and are only billed for one!)
We will create a single private Cloud SQL instance, and “connect” it to our Shared VPC using private service access.
Here Comes The Practical Part! 👩🔧
The developer-envs repo contains all of the relevant IaC and GitOps code.
Infrastructure-as-Code (IaC)
No need to do this manually. We will be using Terraform as Infrastructure-as-Code to bootstrap this for us. Show me the code!
We’ll use Terraform Kubernetes Provider for setting up K8s namespace per environment, as well as creating general ConfigMaps that contains infra related parameters (for example, PubSub topic name, GCP Project ID, etc)
I used Google’s Terraform Modules as part of Cloud Foundation Toolkit throughout the solution and found it quite easy to use. It also introduces some of Google’s best practices so definitely check it out.
Using an infra-as-code tool (such as Terraform) is crucial to this concept — since the whole point is to reduce and automate toil that involves human error and to keep all configurations aligned as you scale. A bit more work for you now for much less work later.
GitOps
Next, we’ll also use ArgoCD to control and deploy our different environments in K8s. ArgoCD is a popular GitOps continuous delivery tool that, in my opinion, fits well with our multi-tenant use case. Show me the code!
We will define most of our K8s resources as YAML files, and we will use Kustomize to customize our configuration.
Kustomize is a configuration tool that allows you to define a “base” configuration, and many “overlays” on top of that, all sharing the base configuration (sort of a poor man’s inheritance). This is ideal for situations where you have multiple environments, and you want them all to share a common configuration ancestor.
Lucky for us, our CD solution, ArgoCD, supports Kustomize as an integration.
I think Kustomize is simple and easy to use, but of course, you can use a different tool (like Helm) instead.
Example Microservices
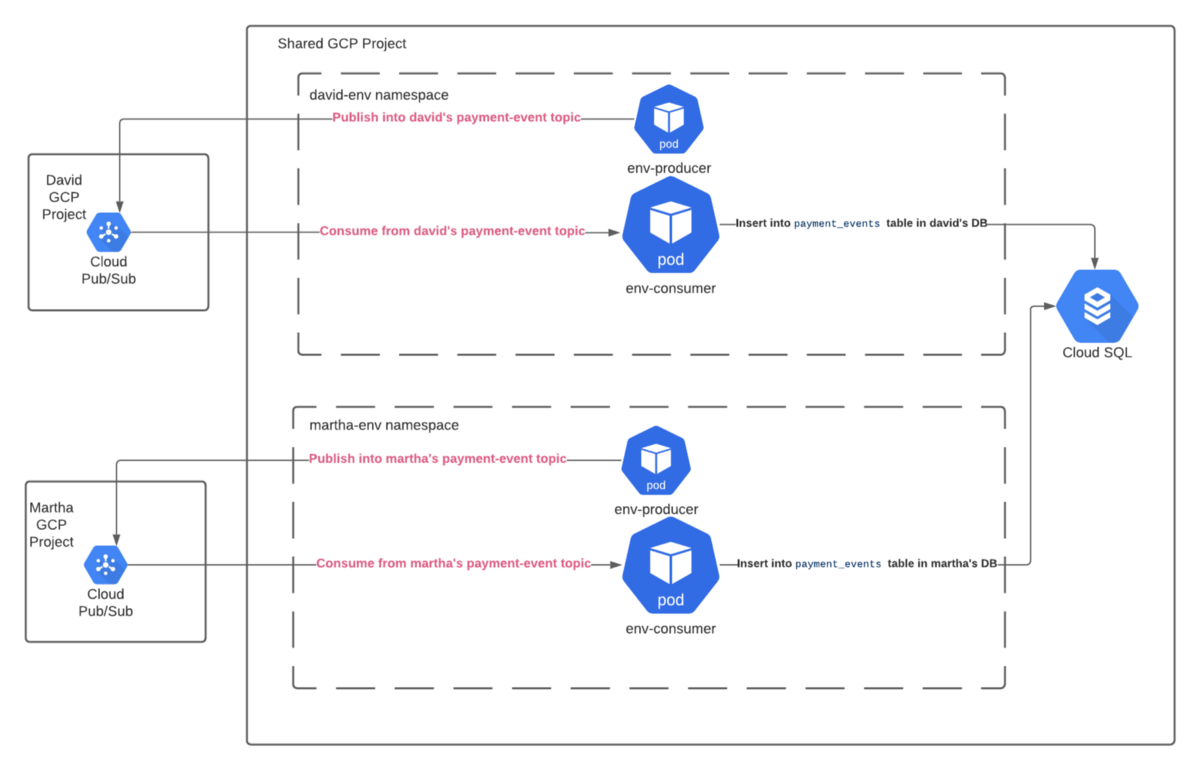
We will deploy two fairly simple and naive microservices written in Go.
The env-producer microservice will periodically publish payment events over a Pub/Sub topic every 10 seconds.
The env-consumer microservice will consume the “payment events” messages from Pub/Sub and persist those events to a table in PostgreSQL.
The key thing about these services is that our multi-environment setup is opaque to them, since we’re exposing our environment details as environment variables. Separating the configuration from the code is a key Twelve-Factor practice that it’s good to be aware of.
In essence, these microservices will run separately on each environment, integrating only with the environment-specific resources.
Getting Up and Running 🏃🏻♂️
To get this up and running, clone the example repo and follow the README.md instructions.
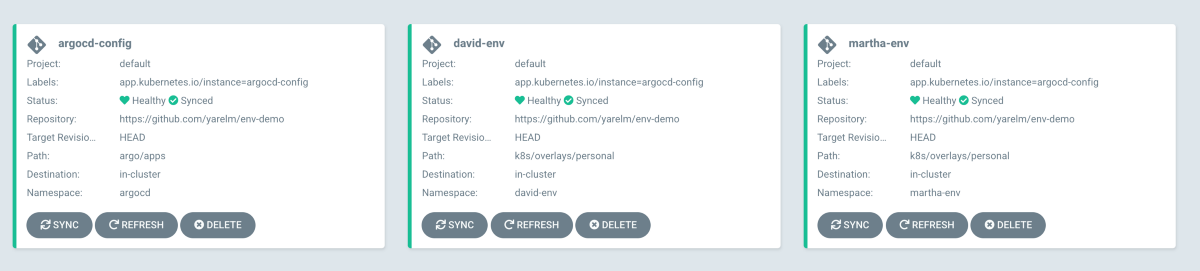
This serves as a place where you can track all of your environments in a single dashboard. Naturally, you may want to add your other environments here as well (such as dev and prod), perhaps in a different ArgoCD “project”.
Notice there is an application called argocd-config that is responsible for self-syncing ArgoCD config and installation files, and 2 additional applications — one for each developer.
How to deploy changes to your environment
You’ve made a change in one of the services and want to deploy this change to your environment. What are your options?
Option 1: Building a custom image
You can make a change in the source code, and then build a new container image. Then, a quick modification of the image tag in his application at ArgoCD will quickly deploy the new image.
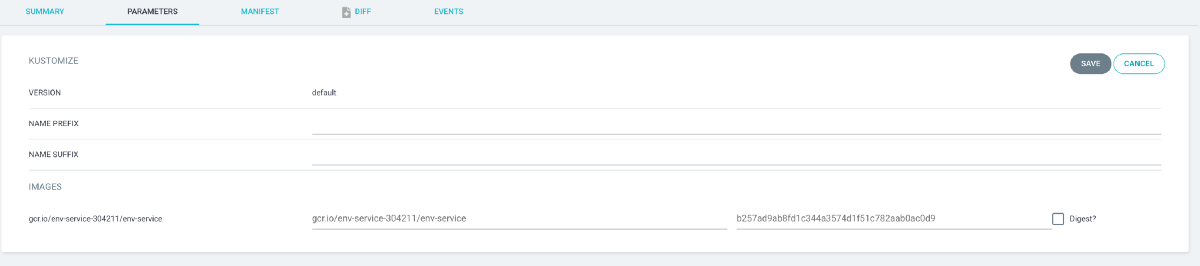
This can be done manually, or automatically through a CI pipeline or custom scripts. (ArgoCD also has a CLI which can be used to automate this)
Option 2: Running it locally
Wait… What? Isn’t it counter-intuitive to what we are trying to do?
Introducing Telepresence. Telepresence is one of the coolest tools that I have encountered lately. I’ve used it many times and it helped me boost my productivity as a developer.
It’s a bit hard to explain what it does in a sentence, but I’ll give it a go. Here is a description I grabbed from their website:
Telepresence substitutes a two-way network proxy for your normal pod running in the Kubernetes cluster. This pod proxies data from your Kubernetes environment (e.g., TCP connections, environment variables, volumes) to the local process. The local process has its networking transparently overridden so that DNS calls and TCP connections are routed through the proxy to the remote Kubernetes cluster.
Or in simpler terms: It allows you to run your service locally, on your machine, while it proxies incoming and outgoing connections, environment variables, and volumes, to the K8s cluster. That’s nice! 👍
So, let’s say you made a change in the env-consumer microservice and want to test it out. So you run:
And in a matter of seconds, it’s deployed and running with your new change.
In essence, what it does is replace your service pod with a proxy pod, and then it runs your service locally while talking to the proxy pod.
The cool thing here is that you are running a local app, but actually you’re connected to both PubSub and Cloud SQL (PostgreSQL) remotely!
And, this is done without us changing the application code, or setting up certificates and secret keys. Same code in the personal environment as in production!
When I’m done, I type Ctrl+C and the image reverts back to what it was before. Happy days! 🤩

Now imaging yourself fixing a bug, running Telepresence, waiting a few seconds, figuring out you caused the service to crash. Oh yeah…you fix that again. The feedback loop here is pretty quick! 😁
Notice I didn’t build any Docker image here. I’m building the modified source code and running the executable locally. You can also make it build the Docker image and replace it instead.
Personal Environments and Onboarding
Ezekiel has just joined the team as a developer! Welcome! He got his laptop and some swag. Yay! 🥳
As part of his onboarding, you’re asked to prepare a personal environment for Ezekiel so he can tinker with the application, the infrastructure, and perhaps make some small changes and see their impact.
How to make that happen:
- Edit the
tf/personal.tfvarsfile and add Ezekiel to the list of tenants:
2. Apply the change by runningterraform apply -f personal.tfvars
3. Add an ArgoCD application for Ezekiel’s environment by appending the following snippet into argo/apps/applications.yaml, then commit, and push the change.
That’s it! As ArgoCD is synced to track the apps folder, it will automatically notice ezekiel-env was added, and will ready the environment. I’m sure Ezekiel will be happy.
Personal Environments and Offboarding
Oh, noes! David is leaving the team to explore other opportunities!
Too bad, we will miss him. ⭐️ 😩
But hey, now we get to see how easy it is to clean up his personal environment. 😌
Just head to argo/apps/applications.yaml and delete the david-env application definition, commit, and push. As ArgoCD is synced to track the apps folder, it will automatically notice david-envwas deleted, and will delete the environment.
Afterward, you should delete the environment infra by deleting david from the tenant’s list at tf/personal.tfvars followed by terraform apply -f personal.tfvars
That’s it! No trace of David💀
👣 Next Steps
If you want to adapt this to your organization, feel free to do so. But, you will have to take additional things into considerations such as:
Just a POC
As noted, this is a POC and is designed for example and “getting-started” purposes. Some parts of the implementation were simplified for brevity. Please don’t treat the implementation as best practices, and feel free to adapt it to your requirements and preferences.
Security
As I mentioned in the previous chapter, security can be a concern with this solution. There are a few possible ways for you to improve the security and isolation based on this solution (for example, RBAC, Network Policies, Resource Quotas, Pod anti-affinity. Check this for more info)
Multi-tenancy
Multi-tenancy examples were given here for cloud services such as GKE, Pub/Sub, and Cloud SQL, however, you can adapt these concepts to other cloud services as well.
Per-developer GCP Project
The current per-developer GCP project scope is quite thin. This is a baseline for extending and improving this project scope. For example, you can setup routing for namespace-specific logs and metrics to be sent into a specific developer GCP project. Another example, the developer GCP project can be used to launch custom resources that are not part of the project mainline, in order to test things work as planned. The per-developer GCP project isn’t a requirement but rather a prospect, so you can omit it if you wish.
Shared VPC
We are using a Shared VPC, which gives your various GCP personal projects the ability to share the same VPC network. This has some IAM prerequisites you need to take into account. For example, your developer’s IAM user should have compute.networkUser role in the Host project in order to create resources in the Shared VPC.
Alternative Solutions
The following alternatives aim to provide a solution. Some aren’t free. It seems these alternatives do not provide a “full-stack” solution when it comes to tailoring the infrastructure to the deployment configuration as in our POC (as much as I‘m aware). Instead, they are mainly aimed at the Kubernetes part. Each has its own pros and cons depending on your context, so do take these into considerations.
That’s it! Hope you enjoyed it 🙂
At DoiT International, We Architects & Engineers always seek to bridge the gap between Infrastructure and Software Development, as we believe both sides share a common goal towards productivity and reliability.
Thanks for reading! To stay connected, follow us on the DoiT Engineering Blog, DoiT Linkedin Channel, and DoiT Twitter Channel. To explore career opportunities, visit https://careers.doit.com.