Recently in the AWS re:invent 2024, there was an announcement for Amazon S3 Tables that provide fully managed Apache Iceberg tables optimized for analytics workloads. These tables will have managed storage Iceberg format table which can be managed using s3tables API and for the data operations, this can be integrated with Apache Spark or AWS-based analytical services — Amazon EMR, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight, Amazon Data Firehose.

Getting started
First of all, you will be required to create a table bucket either using the console or AWS CLI and here you have the option of enabling this table bucket integration with AWS analytics services mentioned above.
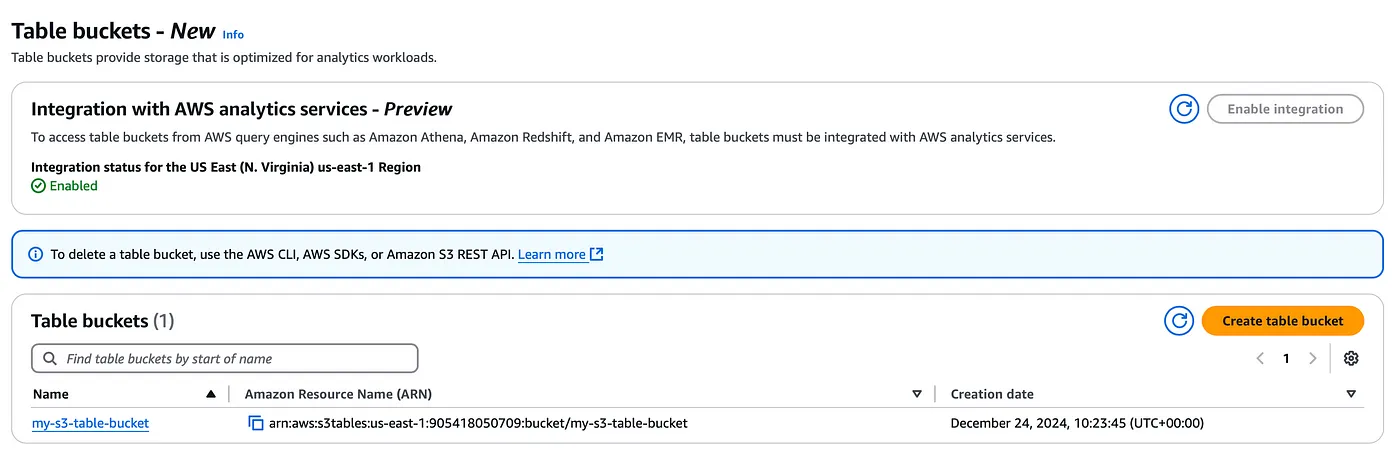
S3 Table bucket console
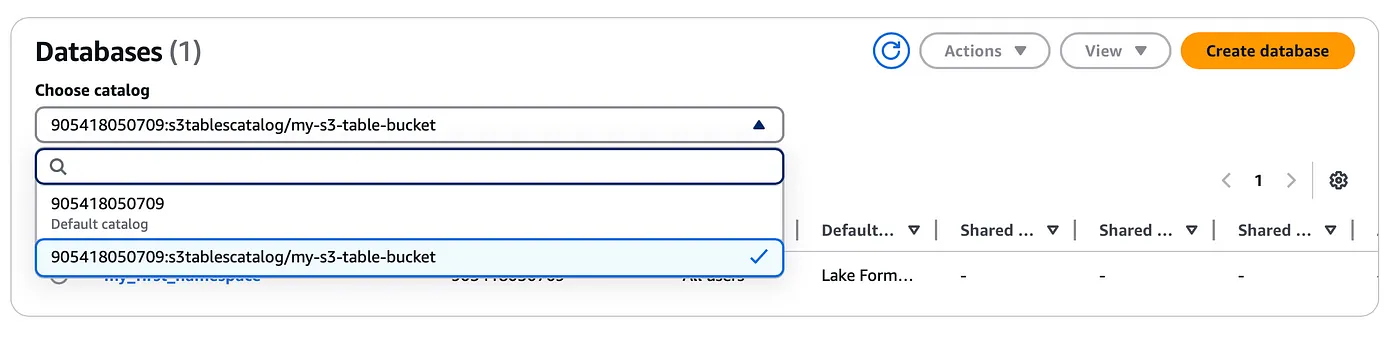
Once you create the table bucket you will now need to create a namespace (Think of this as a logical database that will have multiple tables within it) inside which will have our tables.
aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace
aws s3tables create-table \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace \
--name my_first_table --format ICEBERG
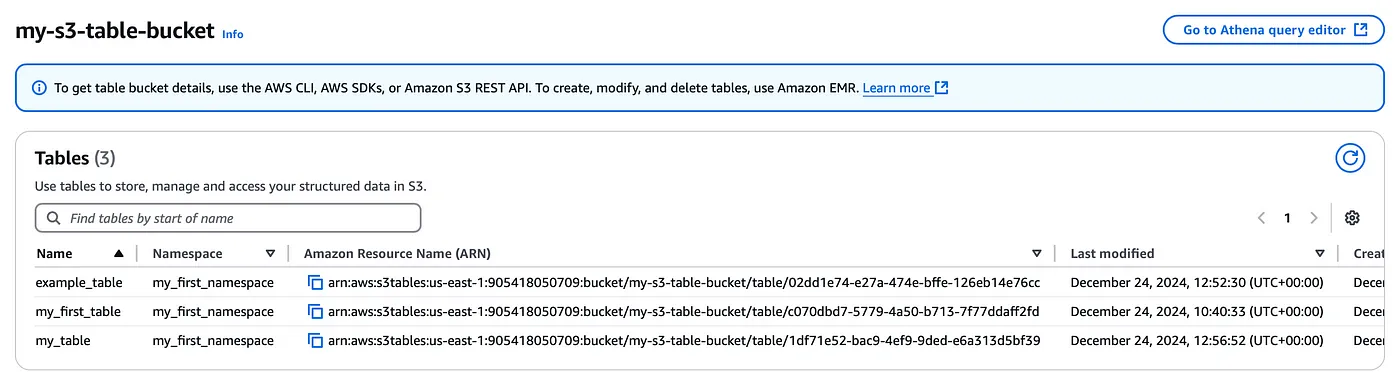
The table format is based on the Apache Iceberg framework, the underlying storage has both the table data and its metadata. With S3 tables you do not have to worry about table maintenance, Amazon S3 offers maintenance to enhance the performance of your S3 tables or table buckets. These maintenance options are file compaction, snapshot management, and unreferenced file removal. These options are enabled by default. You can edit or disable these operations through maintenance configuration files. However, you can configure the maintenance job parameters to the parameter value that works well for you. You can review the job status using the s3tables API
aws s3tables get-table-maintenance-job-status \ --table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \ --namespace="mynamespace" \ --name="testtable"
Before we integrate S3 tables with analytical services, you will need to complete the prerequisite steps.
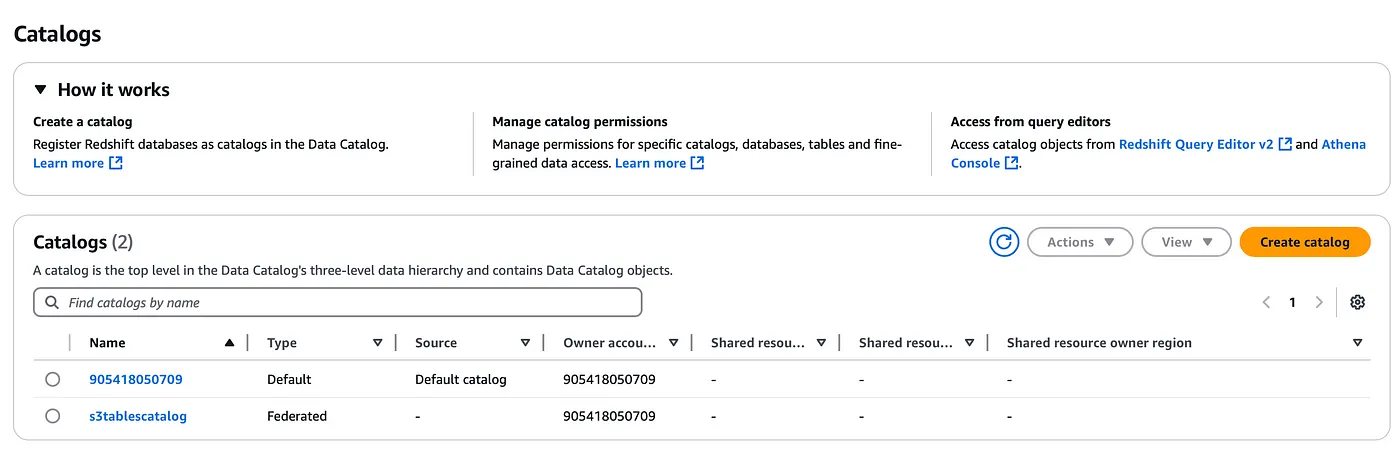
Create a new catalog for S3 tables
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'
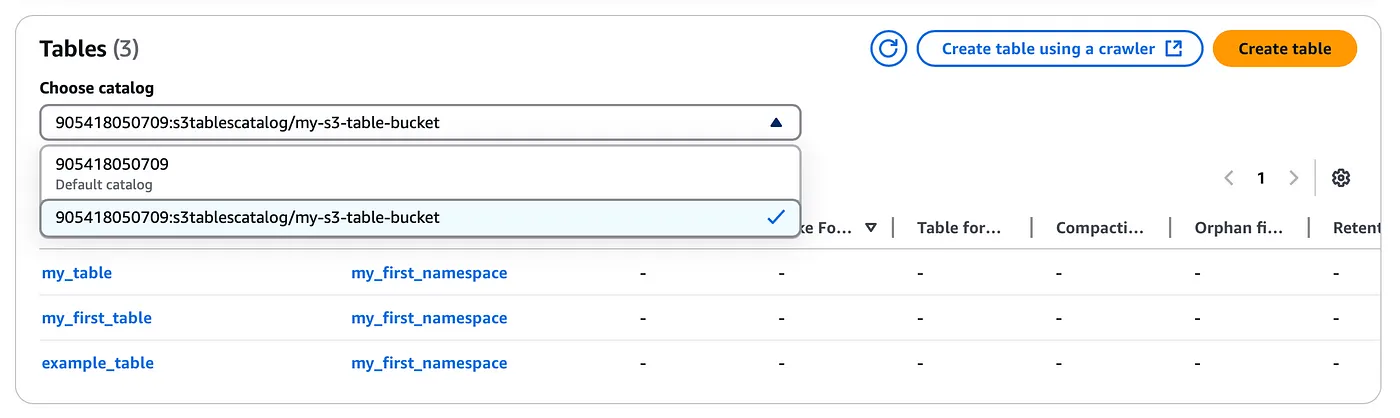
This catalog will be registered under the AWS LakeFormation and likewise, you should also be able to see the namespace and the table we created earlier LakeFormation console (You will need to use the dropdown option to select the S3 table catalog we created above)
Integration with Amazon EMR
Now coming to the fun part! Here we integrate these S3 tables with AWS services. Firstly I will start with Amazon EMR and provision an Iceberg-enabled EMR cluster with Apache Spark. And then login to the primary node of the cluster using SSH.
Start the spark-shell
spark-shell \ --packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \ --conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \ --conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
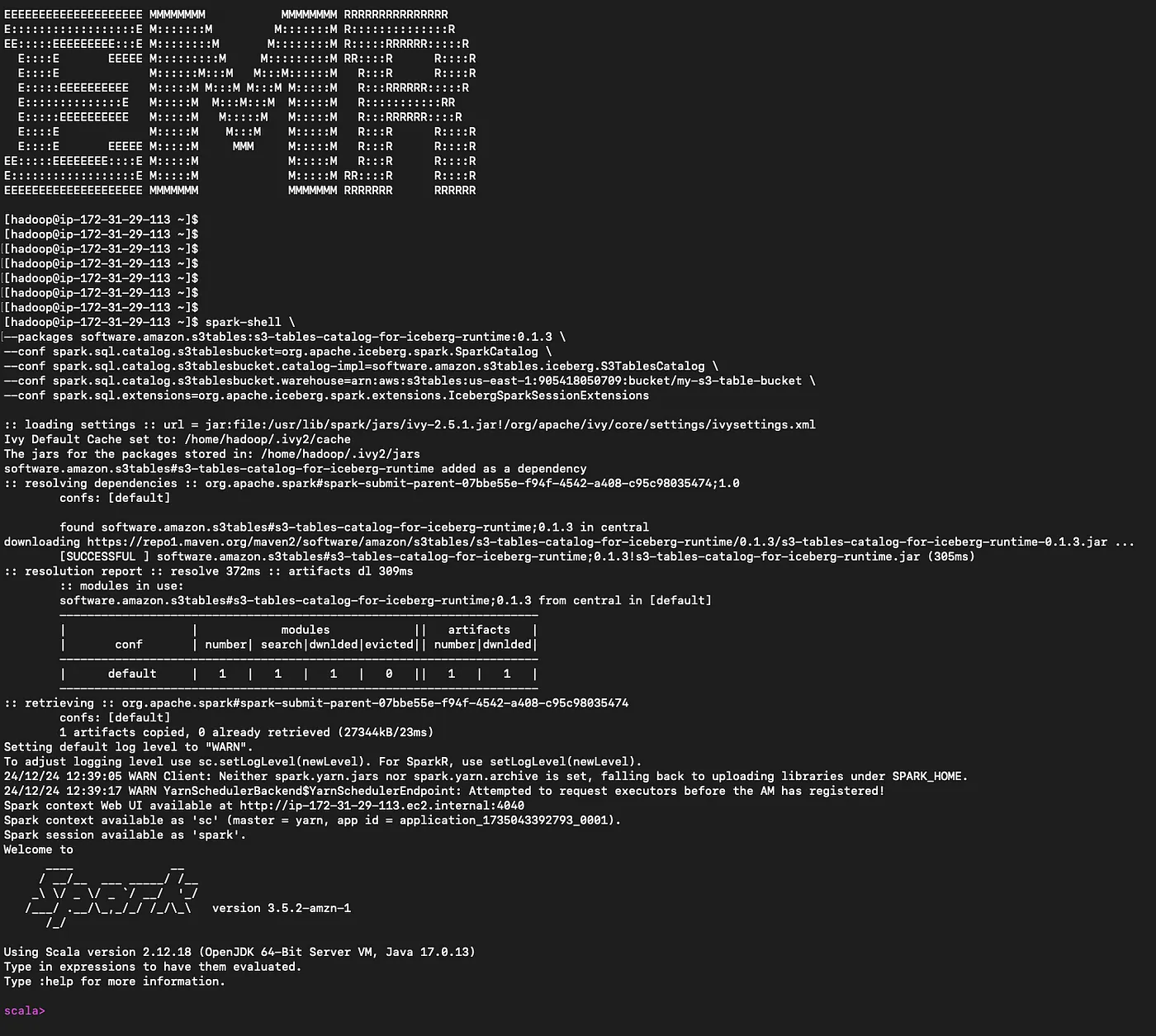
Make sure you have correctly followed the pre-requisite mentioned for the integration. For Amazon EMR, you will need to Attach the AmazonS3TablesFullAccess policy to EMR_EC2_DefaultRoleand also provide appropriate catalog, namespace, and table-level LakeFormation permissions to the EMR_EC2_DefaultRole
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()


If you have a sample parquet data on S3 you can read it and create a S3 table for it and query it
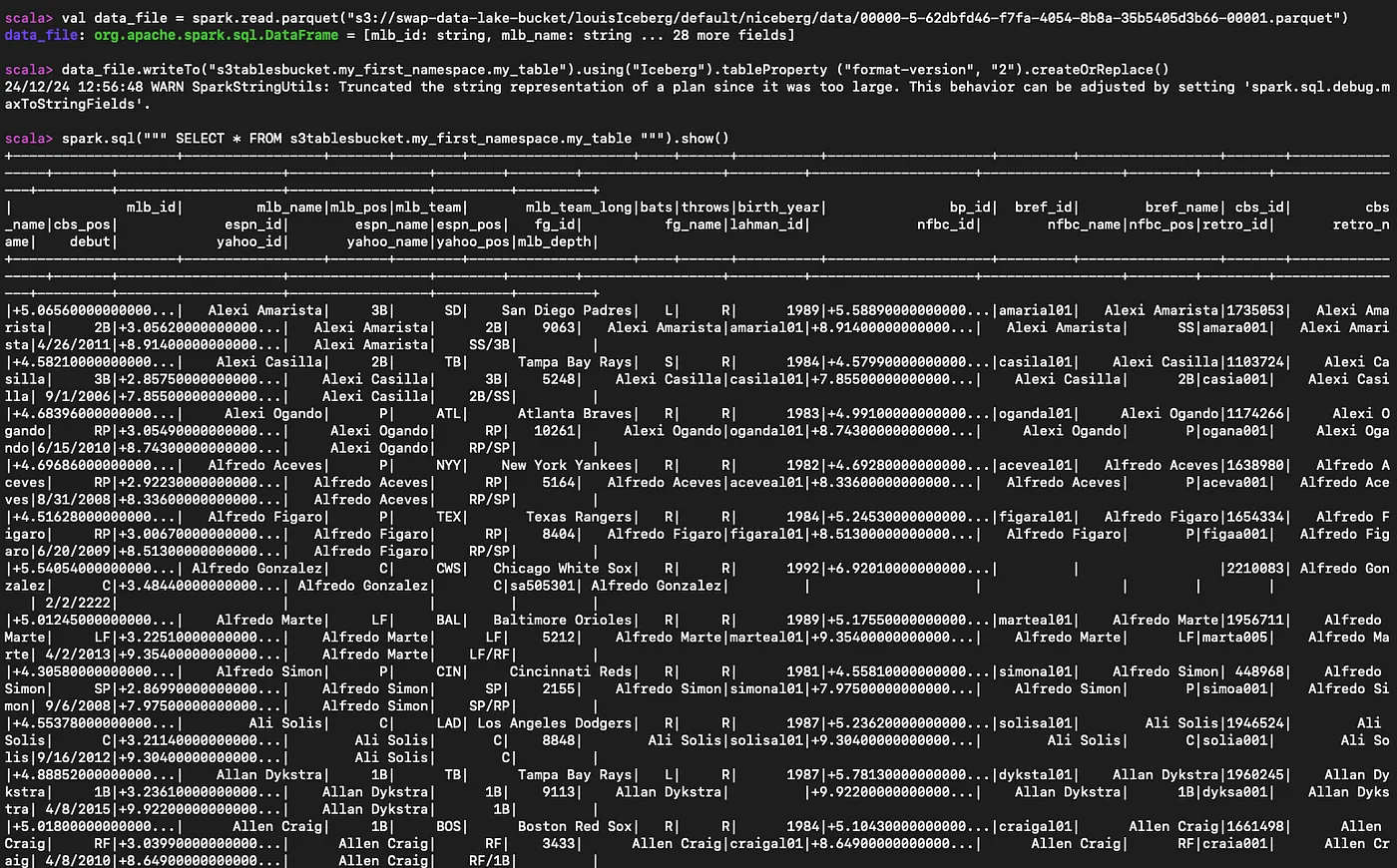
#Read the parequet file
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new table
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we created
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
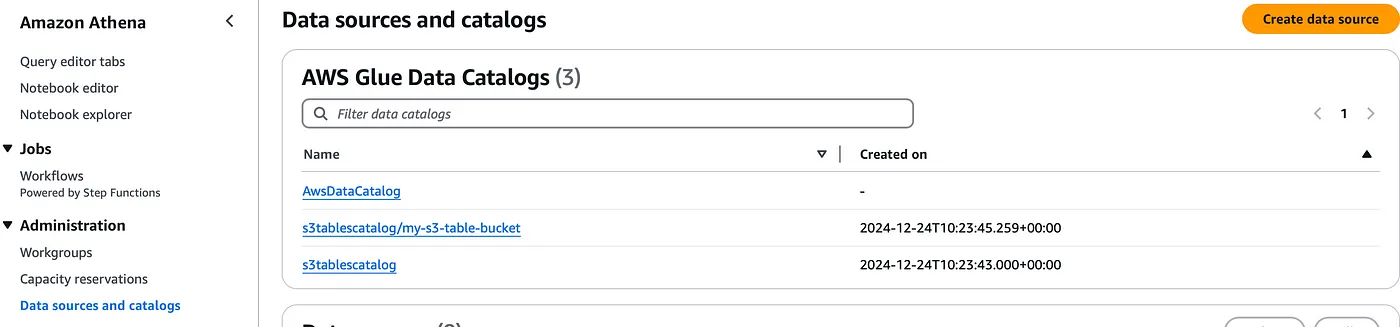
Integration with Amazon Athena
Let's integrate this table with Amazon Athena now! Since we have created a catalog for S3 tables, this can be viewed under the Data sources and catalogs in the Athena console and you can select the drop-down option in the editor to view the s3 tables
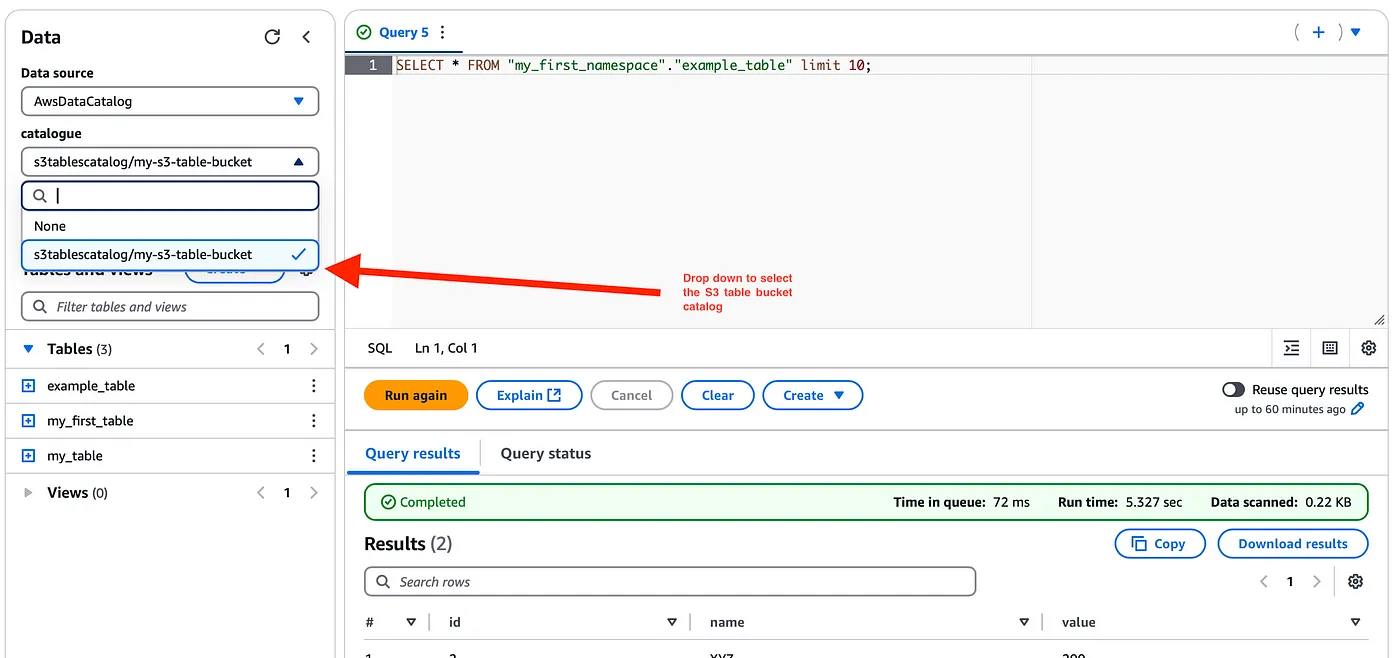
Now you can readily query these tables just as native Glue catalog tables in Athena
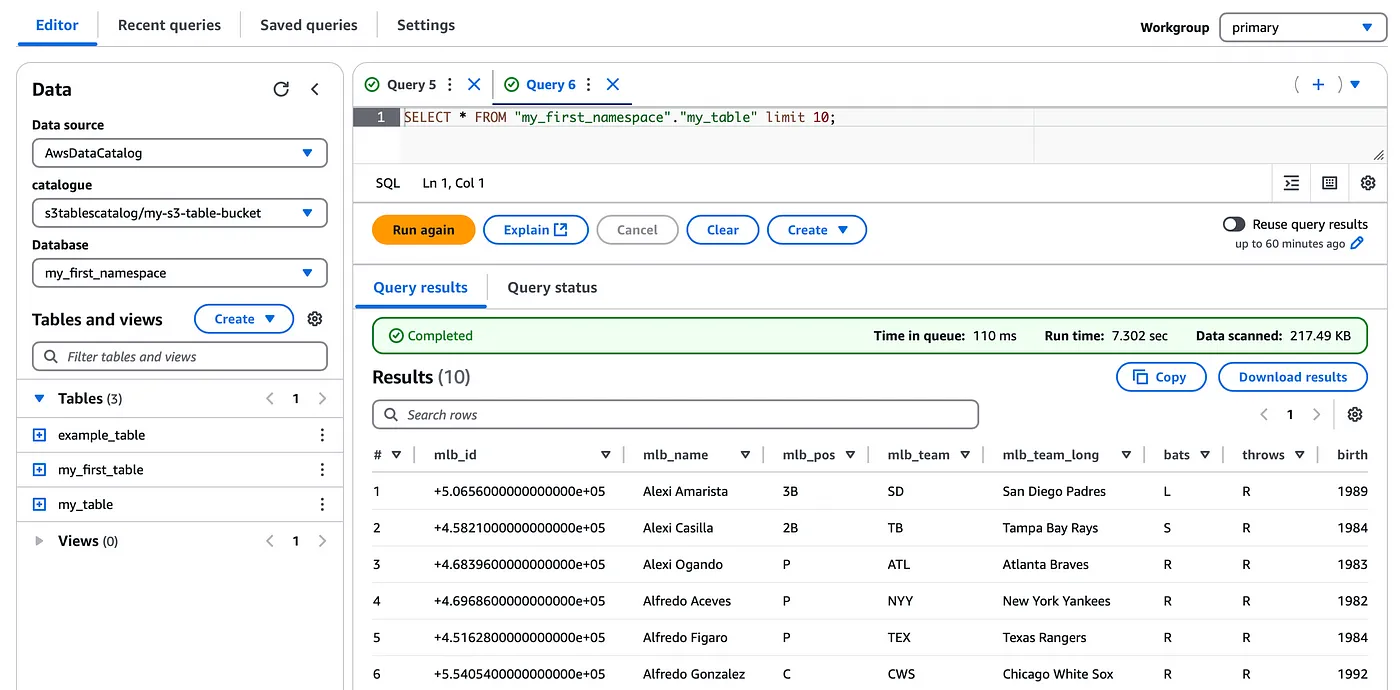
Note that since the s3 tables are managed by S3 you do not have access to the underlying S3 data location and cannot query the manifest files as when compared to querying Iceberg table metadata for Amazon Athena-based tables.
Conclusion
Amazon S3 tables allow you to create logical tables on top of your data in S3 which is stored in parquet format for optimized read performance and these tables are based on Iceberg format which not only supports ACID transactions but also gives you the ability to perform updates, deletes, insert alongside time-travel queries for your data. This is all managed by Amazon S3 for you with the added benefits of S3’s durability, scalability, and performance.
If you’d like to know more or are interested in our services, don’t hesitate to get in touch. You can contact us here.