











Infrastructure as code (IaC) is hard. Often, you need to set up infrastructure (nowadays usually with Terraform) and you start writing a code that fits your specific use case.
Normally, you’ll have limited time and will end up hardcoding all the default values, as well as one or two big files entailing your entire work. A lot of folks think something like; “I’ll just make it work now and figure out later how to improve it when I have some extra time to make it better”.

As time goes by, you get another task to do. By this time you’ve already forgotten what exactly you’ve done to “make it work now”. Or, someone else needs to dive into your code to understand what it does, so that the code can now fit both the previous and the new task at hand.
There’s also a huge terrifying fear of breaking the stuff that works just because you’re willing “to make it better”.
I’ve found myself walking that road many times, and I haven’t found a way to make Terraform a bit friendlier and easier to debug. Until I saw this blog post by Yevgeniy Birkman; “5 lessons learned from writing over 300,000 lines of infrastructure code”.
It has really opened my eyes to how to make Terraform more robust, cleaner, friendlier, and most importantly, how to gain the confidence you need to make the necessary changes or improvements.
I’d like now to share some of my own advice and experience on refactoring Terraform. The following is a recap for the slides you will find at the end of this article.
Monolithic Terraform
When working within a large TF file, one small mistake can break everything. It also makes Terraform much harder to debug, and there is a lack of convenience when you need to find the spot/section that you need to work on is very time-consuming. This pattern eventually leads to code duplication and slower development cycles.
10000ft View Approach
Being able to quickly find what you’re looking for during development or debugging a critical issue is paramount of working with Terraform.
The Terraform plan consolidates all files into one execution, and we can definitely use that to our advantage by creating smaller files with much better visibility. Normally, these smaller files would build up as a more reusable, and composable module.
Module Anatomy
The “300000 lines of infrastructure code” was a great starting point and I took it a step further by creating a scaffold that I use on every module. This scaffold provides better visibility and guidelines for developing a module.
There are no hard-coded values, each hard-coded value becomes a default variable, and every module attribute is a variable (some required, some are default). Every module should have the following structure:
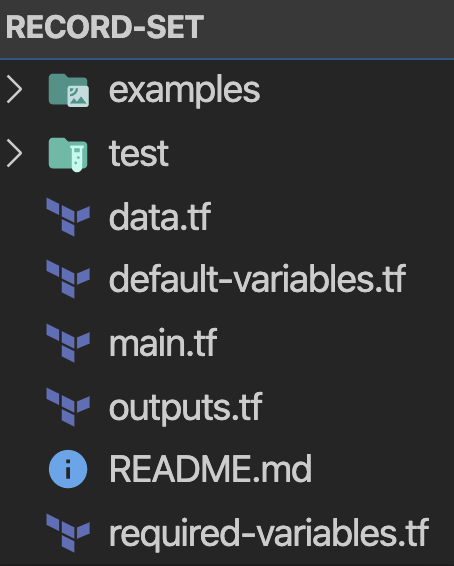
The idea is to place elements where they belong. If the main .tf file is larger than 30 lines, break it into logical files i.e., ec2.tf, autoscaling.tf, etc.
A good practice is to have the ‘examples’ folder to be used for the development of the module and also serve as a usage example for future reference. When I start a new module, I use the following snippet to create that scaffold:
➜ export module_name="sample"
➜ mkdir -p $module_name/examples $module_name/test
➜ cd $module_name && touch \
main.tf \
versions.tf \
default-variables.tf \
required-variables.tf \
outputs.tf \
data.tf
3-Tier Modules Structure
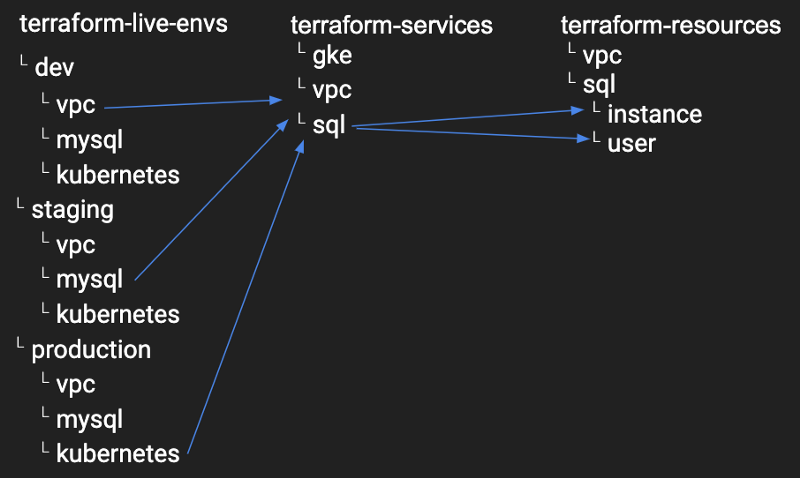
Create and extend your own library of primitives building blocks (terraform-resources)

Then build services from these primitives blocks (terraform-services)

Deploy end-to-end environments from services (terraform-live-envs)

The goal is to isolate each (live) environment (dev, staging, production), then take each component in that environment and break it up into generic service modules. Break each generic service module into resource modules as you want each module to do just one thing, and be as decoupled as possible.
Let’s take a walk through the following example:
You have a deployed mySQL instance on Google Cloud SQL (terraform-live-envs) which is built on top of a generic service called “sql” which contains two modules resources (instance & user).
Refactoring Terraform code
Create a new bucket for the new Terraform state to be stored in. Then, rewrite your new code into the 3-Tiers modules (as illustrated above and detailed in the slides). Import each of the resources into your live-envs Terraform code.
Terraform will then show you the execution plan for the import operation:
[1] values that exist in the deployed version but not in your code will be marked with a minus sign for removal.
[2] values that do not exist in the deployed version but do exists in your code will be marked with a plus sign for addition.
Your goal should be to get to point when there is no change in the plan.
Slides
The following slides contain a brief introduction to Terraform, as well as my suggestions on how to refactor existing Terraform modules:


