












Amazon Aurora DSQL (Distributed SQL) introduces a new approach to relational databases, leveraging distributed SQL architecture to deliver high scalability, robust availability, and seamless support for distributed transactions. Adopting Aurora DSQL requires more than excitement (and I am a bit excited; I already got told to tone down this blog) — it calls for a clear understanding of how it operates and whether your data patterns match its capabilities well.
In this blog, we’ll dive into how Aurora DSQL works, explore data patterns that work well in its environment, and discuss determining if it fits your workload.
How Does Aurora DSQL Work?
Aurora DSQL’s power comes from its innovative design, which disaggregates database components into independent, scalable services. By using the huge speed and bandwidth of modern cloud networking and a distributed architecture, Aurora DSQL achieves a balance between scalability, performance, and consistency. Let’s start with a high-level architecture diagram showing the 5 different components in Aurora DSQL:
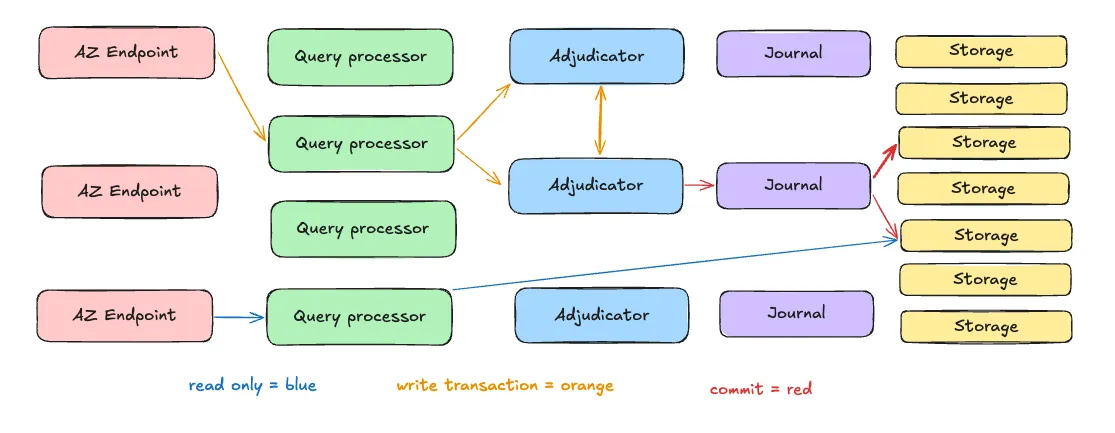
Disaggregated Architecture
Aurora DSQL separates query execution, transaction management, and storage into specialized services:
- Query Execution Layer: Runs SQL queries in parallel, scaling horizontally as demand increases.
- Transaction Management Layer: Coordinates distributed transactions using techniques like optimistic locking to ensure consistency.
- Storage Layer: A shared-nothing, distributed system replicates data across multiple nodes for durability and fault tolerance.
Each service is designed to scale independently, ensuring that the system can handle workloads of varying intensity without bottlenecks.
MicroVMs for Transaction Isolation
Aurora DSQL runs each transaction in its own microVM, providing complete isolation. This architecture eliminates contention between transactions, particularly:
- Read-Heavy Workloads: Reads don’t cause locking or generate undo logs, making them lightweight and fast.
- Concurrent Transactions: Multiple transactions can run simultaneously without interfering with each other, enabling high concurrency.
Optimistic Locking
Aurora DSQL’s transaction model relies on optimistic locking:
- Transactions assume minimal contention and only check for conflicts at commit time.
- If a conflict is detected (e.g., another transaction has modified the same data), the transaction fails, and the application must retry.
Optimistic locking works best for workloads with low write contention but requires robust retry logic for higher contention scenarios.
The Adjudicator and Journal
Key architectural components ensure Aurora DSQL’s consistency and durability:
- Adjudicator: Enforces a globally consistent commit order for transactions, resolving conflicts and maintaining strong consistency.
- Journal: A distributed log that records transaction changes, providing durability and enabling recovery from failures.
What Data Patterns Work Best for Aurora DSQL?
Aurora DSQL excels with certain data patterns, particularly those that align with its distributed and disaggregated nature. Here’s a closer look at the patterns that thrive and how to identify them in your workload.
1. High-Concurrency Workloads
Aurora DSQL is ideal for applications with many concurrent users or processes, such as:
- E-commerce Platforms: Handling simultaneous transactions for inventory updates, purchases, and user activity.
- Social Media Applications: Managing likes, comments, and user interactions across millions of active users.
- SaaS Applications: Supporting multiple customers with isolated workloads while sharing the same database infrastructure.
To identify if your workload fits this pattern:
- Look at your peak concurrent user numbers and query activity.
- Analyze whether contention (e.g., multiple processes writing to the same data) is manageable with optimistic locking.
2. Read-Heavy Applications
Since reads in Aurora DSQL don’t cause locks or undo generation, read-heavy workloads perform exceptionally well. Examples include:
- Dashboards and Analytics: Applications where real-time data updates are viewed more frequently than they are written.
- Content Delivery Platforms: Streaming or news applications where users mostly consume content.
To assess your read-write ratio:
- Monitor query logs to see the percentage of read operations compared to writes.
- Use Aurora’s performance insights or database monitoring tools to measure read query latency and throughput.
3. Geographically Distributed Data Access
Aurora DSQL’s distributed nature makes it a great fit for applications serving global users:
- Gaming Platforms: Multiplayer games where players from different regions interact in real time.
- Collaboration Tools: Document sharing or chat applications requiring low-latency access across continents.
To identify this pattern:
- Map your user base geographically and determine if latency-sensitive queries originate from multiple regions.
- Evaluate whether a centralized database causes latency issues for distant users.
4. Low-Contention Write Workloads
Aurora DSQL’s optimistic locking shines when write contention is low. Examples include:
- Partitioned Data: Applications where writes are naturally isolated to specific partitions, such as per-user or per-tenant updates.
- Event Logging: Systems where events are written independently with minimal overlap.
To verify if your workload fits:
- Analyze write operations to see if they frequently target the same rows or objects.
- Check for natural partitioning opportunities in your schema (e.g., sharding by user ID or tenant).
5. Hybrid Transactional and Analytical Processing (HTAP)
Applications that blend transactional and analytical queries benefit from Aurora DSQL’s ability to handle both workloads efficiently:
- Financial Dashboards: Combining real-time transaction updates with analytical summaries.
- Inventory Systems: Allowing operational updates while providing immediate insights into stock levels.
To confirm this pattern:
- Identify workloads that involve both real time updates and analytical queries.
- Ensure long-running analytical queries can be optimized to fit within Aurora DSQL’s 5-minute query timeout.
Is Aurora DSQL Right for You?
Aurora DSQL is a powerful database system for modern applications that need to scale horizontally while maintaining consistency. It excels with high-concurrency, read-heavy, partitionable, and globally distributed workloads. However, it may require careful schema design and application logic to handle limitations like optimistic locking and query timeouts.
By analyzing your data patterns and aligning them with Aurora DSQL’s strengths, you can determine if this innovative distributed database is the right fit for your needs. With the right design, Aurora DSQL can offer unparalleled scalability, performance, and resilience for your application.
Have Questions About Making Aurora DSQL Work for Your Organization?
If you’re still wondering how to apply these insights to leverage Aurora DSQL — or any other GCP or AWS data solution — for success in your organization, we’re here to help.
At DoiT, our team is staffed exclusively with senior engineering talent. We specialize in advanced cloud consulting, architectural design, and debugging services. Whether you’re planning your first steps with distributed databases, optimizing an existing system, or troubleshooting complex issues, we provide tailored, expert advice to meet your needs.
Reach out today and let us help you unlock the full potential of your cloud infrastructure.



