Part 2
In Part 1, we described the challenges of slow, costly optimization processes that never come out well enough the first time. Whether it is Machine Learning (ML) training, A/B testing of websites, or choosing the right inputs for a factory, each cycle is expensive, and you want to converge to a good result as rapidly as possible. Vertex AI Vizier on Google Cloud makes this happen by providing suggestions for parameters for each trial.
Just an Advisor
“Vizier” is a title for a king’s advisor, derived from Arabic وزير wazīr through Persian and Turkish. The Vizier advises on, but does not decide, royal policy. And this is how Vizier’s black-box optimization works. It does not carry out the optimization trials for you. In contrast, the hyperparameter tuner services provided by GCP and AWS does everything for you. You give it a range of hyperparameters; for example, the learning rate ranging continuously from 0 to 1; or minimum child weight as an integer parameter from 1 to 3. You create the hyperparameter tuner client, then fire and forget by calling a function like fit(). That function runs for a while, maybe a few hours, and internally executes multiple training iterations, choosing different hyperparameters as it goes. Then the tuner returns the best model it can find.
The Black Box optimization process is out of your control and is invisible to you. (At least as far as the API goes: There are typically monitoring systems in place).
Note: “Black Box” means that your trials are invisible to Vizier. It knows nothing about the ML training or the A/B test. It knows nothing about the gradients, the ups and the downs of the function being optimized inside each trial.
To you, on the other hand, these trials are completely “white-box”: You are in charge.
Advantages
A hyperparameter tuner service seems simpler than Vizier, and indeed Google built its Vertex AI AutoML and its hyperparameter tuners in the AI Platform (the older brand name) on top of a Vizier-based engine. But there are advantages to the Black Box approach in which you interact with Vizier.
Control
You get more control with Black Box Optimization.
The trials are generally in your area of expertise. Your website developers know the ins and outs of your website; your data scientists understand the details of the ML algorithmics. You have thought carefully about how to get the best out of your systems at the lowest cost. With Vizier, you retain full control of the actual ML training: What infrastructure or APIs to use, how many and which GPUs or TPUs, etc.
You can even ignore Vizier’s suggestions and use your own parameters. Of course, usually, you would use the suggestions: After all, that is why you are invoking Vizier. For example, you might read about a new algorithm for your ML, or if the product managers want to try out a new variant that was not in the website A/B testing, you can go ahead and try that. Even when you run the trial with your own parameters, you can still feed the parameters and metrics into Vizier, and it will learn from that, just as it does when you use its suggested parameters
Scalability
Vizier only does the “easy” part of optimizing across multiple trials. It does not do the heavy lifting of ML, which can require lots of specialized hardware. Likewise, it does not do the heavy lifting of the A/B testing of a website or running a factory. This makes it scalable because you handle the actual training or other optimized process, which is the most intense part of the overall workflow, and therefore can apply the best practices most suitable to your exact setup. (In Figure 1 below, your training machines are the “Evaluation workers” under the Vizier REST API.)
Meanwhile, Vizier scalably spawns workers to generate suggestions or suggest when to stop. As its state is stored in a database, rather than inside the context of a single optimization run, it can recover from failure. And because the suggestion workers only do hyperoptimization, not your “heavy lifting”, the Vizier can efficiently scale up these workers.
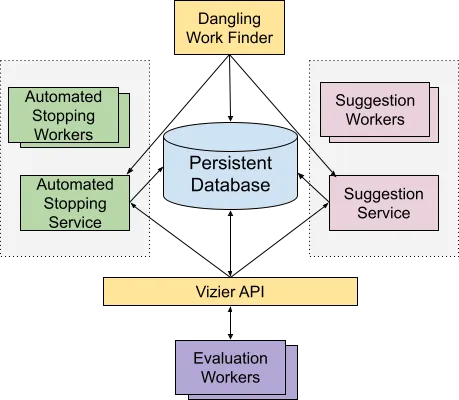
Figure 1. Architecture diagram (Based on the diagram from the research paper.)
Multi-Objective
Most optimization processes, and most hyperparameter tuners, seek to maximize one metric. That is the most common usage of Vertex AI Vizier as well. But you might want to optimize several metrics at the same time. In an A/B test for a website, you might want to both maximize revenue and time on site. Or you might have a two-sided market, and you want the buyers to get good deals, but you also want sellers to maximize profits.
As a simple example to illustrate the concept, you can have a look at this sample Notebook from Google that maximizes two trigonometric functions of the same two input parameters.
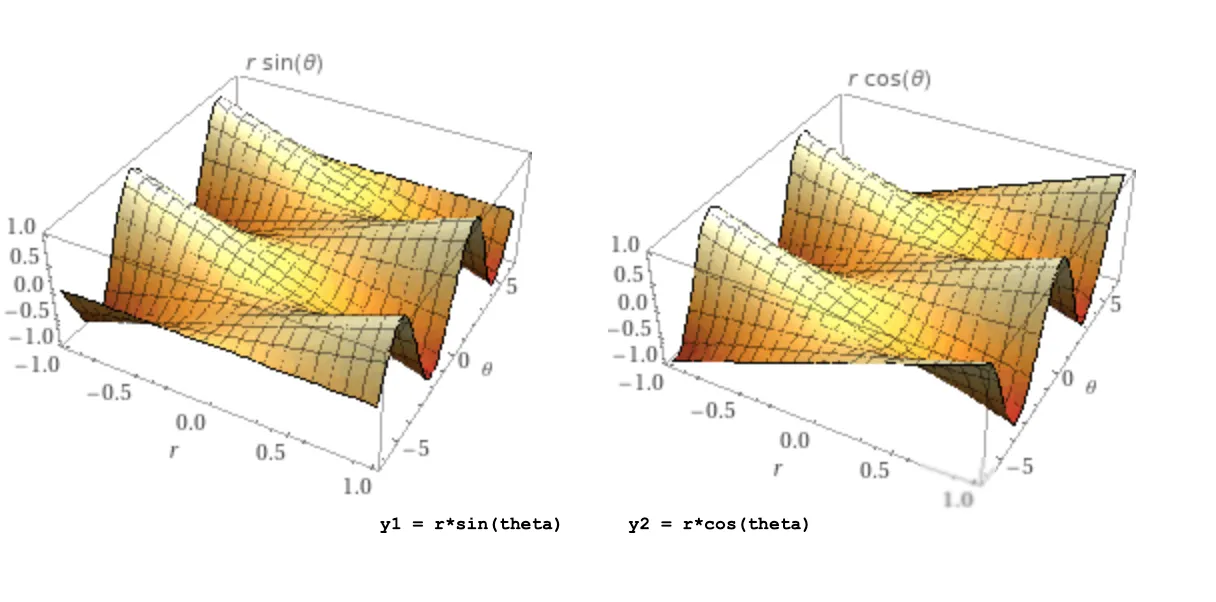
Figure 2. There is no one optimal point for both functions.
Clearly, there is no one point where both metrics are maximized, so Vertex AI Vizier discovers the Pareto frontier, A line on one side of which you cannot make one metric better, without making the other metric worse: The optimum is not one point, it’s a border.
Next: Flexibility, and some of the first Vizier ML notebooks
Vizier is a straightforward system, and you can (and generally, should) use it with default settings. Yet you can also further tune its capabilities. In the next article, we will show how to do that, and also provide some code samples.
See Part 3 “Beyond the basics: Vizier configurability and code samples”